Jemila S Hamid, Pingzhao Hu, Nicole M Roslin, Vicki Ling, Celia M T Greenwood, Joseph Beyene
{"title":"Data integration in genetics and genomics: methods and challenges.","authors":"Jemila S Hamid, Pingzhao Hu, Nicole M Roslin, Vicki Ling, Celia M T Greenwood, Joseph Beyene","doi":"10.4061/2009/869093","DOIUrl":null,"url":null,"abstract":"<p><p>Due to rapid technological advances, various types of genomic and proteomic data with different sizes, formats, and structures have become available. Among them are gene expression, single nucleotide polymorphism, copy number variation, and protein-protein/gene-gene interactions. Each of these distinct data types provides a different, partly independent and complementary, view of the whole genome. However, understanding functions of genes, proteins, and other aspects of the genome requires more information than provided by each of the datasets. Integrating data from different sources is, therefore, an important part of current research in genomics and proteomics. Data integration also plays important roles in combining clinical, environmental, and demographic data with high-throughput genomic data. Nevertheless, the concept of data integration is not well defined in the literature and it may mean different things to different researchers. In this paper, we first propose a conceptual framework for integrating genetic, genomic, and proteomic data. The framework captures fundamental aspects of data integration and is developed taking the key steps in genetic, genomic, and proteomic data fusion. Secondly, we provide a review of some of the most commonly used current methods and approaches for combining genomic data with focus on the statistical aspects.</p>","PeriodicalId":88887,"journal":{"name":"Human genomics and proteomics : HGP","volume":"2009 ","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2009-01-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.4061/2009/869093","citationCount":"145","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Human genomics and proteomics : HGP","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4061/2009/869093","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 145
Abstract
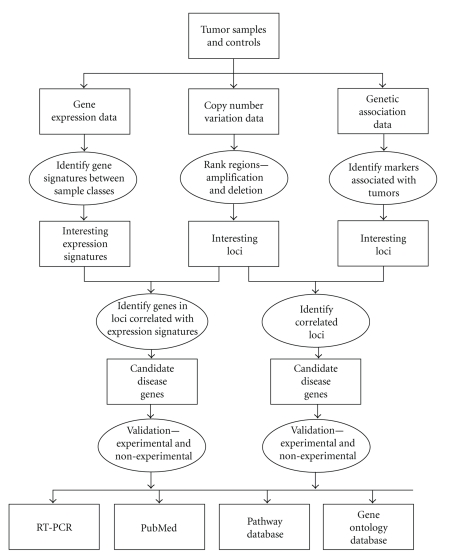
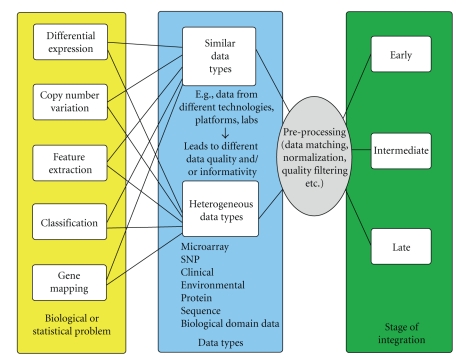
Due to rapid technological advances, various types of genomic and proteomic data with different sizes, formats, and structures have become available. Among them are gene expression, single nucleotide polymorphism, copy number variation, and protein-protein/gene-gene interactions. Each of these distinct data types provides a different, partly independent and complementary, view of the whole genome. However, understanding functions of genes, proteins, and other aspects of the genome requires more information than provided by each of the datasets. Integrating data from different sources is, therefore, an important part of current research in genomics and proteomics. Data integration also plays important roles in combining clinical, environmental, and demographic data with high-throughput genomic data. Nevertheless, the concept of data integration is not well defined in the literature and it may mean different things to different researchers. In this paper, we first propose a conceptual framework for integrating genetic, genomic, and proteomic data. The framework captures fundamental aspects of data integration and is developed taking the key steps in genetic, genomic, and proteomic data fusion. Secondly, we provide a review of some of the most commonly used current methods and approaches for combining genomic data with focus on the statistical aspects.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


