{"title":"AI's Accuracy in Extracting Learning Experiences From Clinical Practice Logs: Observational Study.","authors":"Takeshi Kondo, Hiroshi Nishigori","doi":"10.2196/68697","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Improving the quality of education in clinical settings requires an understanding of learners' experiences and learning processes. However, this is a significant burden on learners and educators. If learners' learning records could be automatically analyzed and their experiences could be visualized, this would enable real-time tracking of their progress. Large language models (LLMs) may be useful for this purpose, although their accuracy has not been sufficiently studied.</p><p><strong>Objective: </strong>This study aimed to explore the accuracy of predicting the actual clinical experiences of medical students from their learning log data during clinical clerkship using LLMs.</p><p><strong>Methods: </strong>This study was conducted at the Nagoya University School of Medicine. Learning log data from medical students participating in a clinical clerkship from April 22, 2024, to May 24, 2024, were used. The Model Core Curriculum for Medical Education was used as a template to extract experiences. OpenAI's ChatGPT was selected for this task after a comparison with other LLMs. Prompts were created using the learning log data and provided to ChatGPT to extract experiences, which were then listed. A web application using GPT-4-turbo was developed to automate this process. The accuracy of the extracted experiences was evaluated by comparing them with the corrected lists provided by the students.</p><p><strong>Results: </strong>A total of 20 sixth-year medical students participated in this study, resulting in 40 datasets. The overall Jaccard index was 0.59 (95% CI 0.46-0.71), and the Cohen κ was 0.65 (95% CI 0.53-0.76). Overall sensitivity was 62.39% (95% CI 49.96%-74.81%), and specificity was 99.34% (95% CI 98.77%-99.92%). Category-specific performance varied: symptoms showed a sensitivity of 45.43% (95% CI 25.12%-65.75%) and specificity of 98.75% (95% CI 97.31%-100%), examinations showed a sensitivity of 46.76% (95% CI 25.67%-67.86%) and specificity of 98.84% (95% CI 97.81%-99.87%), and procedures achieved a sensitivity of 56.36% (95% CI 37.64%-75.08%) and specificity of 98.92% (95% CI 96.67%-100%). The results suggest that GPT-4-turbo accurately identified many of the actual experiences but missed some because of insufficient detail or a lack of student records.</p><p><strong>Conclusions: </strong>This study demonstrated that LLMs such as GPT-4-turbo can predict clinical experiences from learning logs with high specificity but moderate sensitivity. Future improvements in AI models, providing feedback to medical students' learning logs and combining them with other data sources such as electronic medical records, may enhance the accuracy. Using artificial intelligence to analyze learning logs for assessment could reduce the burden on learners and educators while improving the quality of educational assessments in medical education.</p>","PeriodicalId":36236,"journal":{"name":"JMIR Medical Education","volume":"11 ","pages":"e68697"},"PeriodicalIF":3.2000,"publicationDate":"2025-10-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12529426/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Education","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/68697","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"EDUCATION, SCIENTIFIC DISCIPLINES","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Improving the quality of education in clinical settings requires an understanding of learners' experiences and learning processes. However, this is a significant burden on learners and educators. If learners' learning records could be automatically analyzed and their experiences could be visualized, this would enable real-time tracking of their progress. Large language models (LLMs) may be useful for this purpose, although their accuracy has not been sufficiently studied.
Objective: This study aimed to explore the accuracy of predicting the actual clinical experiences of medical students from their learning log data during clinical clerkship using LLMs.
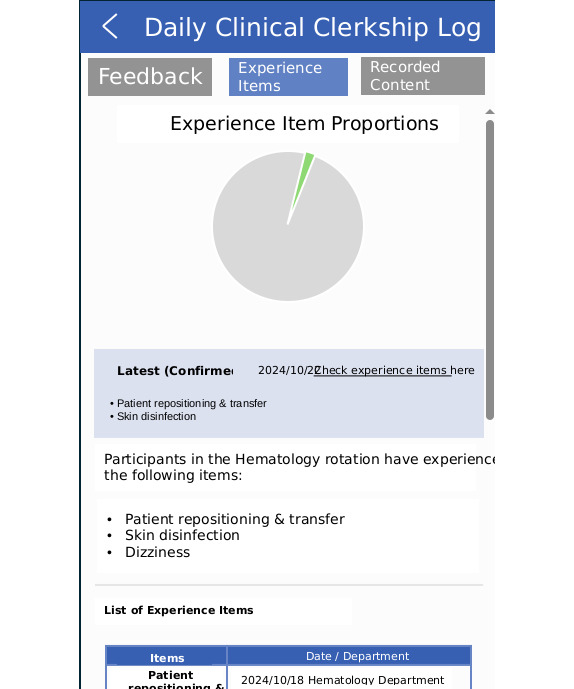
Methods: This study was conducted at the Nagoya University School of Medicine. Learning log data from medical students participating in a clinical clerkship from April 22, 2024, to May 24, 2024, were used. The Model Core Curriculum for Medical Education was used as a template to extract experiences. OpenAI's ChatGPT was selected for this task after a comparison with other LLMs. Prompts were created using the learning log data and provided to ChatGPT to extract experiences, which were then listed. A web application using GPT-4-turbo was developed to automate this process. The accuracy of the extracted experiences was evaluated by comparing them with the corrected lists provided by the students.
Results: A total of 20 sixth-year medical students participated in this study, resulting in 40 datasets. The overall Jaccard index was 0.59 (95% CI 0.46-0.71), and the Cohen κ was 0.65 (95% CI 0.53-0.76). Overall sensitivity was 62.39% (95% CI 49.96%-74.81%), and specificity was 99.34% (95% CI 98.77%-99.92%). Category-specific performance varied: symptoms showed a sensitivity of 45.43% (95% CI 25.12%-65.75%) and specificity of 98.75% (95% CI 97.31%-100%), examinations showed a sensitivity of 46.76% (95% CI 25.67%-67.86%) and specificity of 98.84% (95% CI 97.81%-99.87%), and procedures achieved a sensitivity of 56.36% (95% CI 37.64%-75.08%) and specificity of 98.92% (95% CI 96.67%-100%). The results suggest that GPT-4-turbo accurately identified many of the actual experiences but missed some because of insufficient detail or a lack of student records.
Conclusions: This study demonstrated that LLMs such as GPT-4-turbo can predict clinical experiences from learning logs with high specificity but moderate sensitivity. Future improvements in AI models, providing feedback to medical students' learning logs and combining them with other data sources such as electronic medical records, may enhance the accuracy. Using artificial intelligence to analyze learning logs for assessment could reduce the burden on learners and educators while improving the quality of educational assessments in medical education.
背景:提高临床教育质量需要了解学习者的经历和学习过程。然而,这对学习者和教育者来说是一个沉重的负担。如果学习者的学习记录可以自动分析,他们的经验可以可视化,这将使实时跟踪他们的进步成为可能。大型语言模型(llm)可能对这一目的有用,尽管它们的准确性还没有得到充分的研究。目的:本研究旨在探讨利用LLMs从医学生临床见习学习日志数据预测医学生实际临床经验的准确性。方法:本研究在名古屋大学医学院进行。使用2024年4月22日至2024年5月24日参加临床实习的医学生的学习日志数据。以《医学教育核心课程示范》为模板提取经验。经过与其他llm的比较,我们选择OpenAI的ChatGPT来完成这个任务。使用学习日志数据创建提示,并提供给ChatGPT以提取经验,然后将其列出。开发了一个使用GPT-4-turbo的web应用程序来自动化此过程。通过将所提取的经验与学生提供的更正列表进行比较,来评估其准确性。结果:共有20名六年级医学生参与本研究,共获得40个数据集。总体Jaccard指数为0.59 (95% CI 0.46 ~ 0.71), Cohen κ为0.65 (95% CI 0.53 ~ 0.76)。总敏感性为62.39% (95% CI 49.96% ~ 74.81%),特异性为99.34% (95% CI 98.77% ~ 99.92%)。分类特异性表现不同:症状的敏感性为45.43% (95% CI 25.12%-65.75%),特异性为98.75% (95% CI 97.31%-100%),检查的敏感性为46.76% (95% CI 25.67%-67.86%),特异性为98.84% (95% CI 97.81%-99.87%),手术的敏感性为56.36% (95% CI 37.64%-75.08%),特异性为98.92% (95% CI 96.67%-100%)。结果表明,GPT-4-turbo准确地识别了许多实际经历,但由于细节不足或缺乏学生记录而遗漏了一些。结论:本研究表明,GPT-4-turbo等LLMs可以通过学习日志预测临床经验,特异性高,敏感性中等。AI模型的未来改进,为医学生的学习日志提供反馈,并将其与电子病历等其他数据源相结合,可能会提高准确性。利用人工智能分析学习日志进行评估可以减轻学习者和教育者的负担,同时提高医学教育中教育评估的质量。

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


