Graydon Cowgill, Steven Anthony Strazza, Savannah Wilson, Ranjeeta Odari, Sadia Afrin Bristy, Yongjian Qiu, Sayaka Miura
{"title":"Challenges in Applying DNA-Binding Protein Predictors to Biological Research.","authors":"Graydon Cowgill, Steven Anthony Strazza, Savannah Wilson, Ranjeeta Odari, Sadia Afrin Bristy, Yongjian Qiu, Sayaka Miura","doi":"10.3390/ijms26199785","DOIUrl":null,"url":null,"abstract":"<p><p>DNA binding proteins play a crucial role in regulating gene expression, DNA replication, and chromatin organization. While many DNA-binding proteins have been identified, many unique DNA-binding proteins in non-model organisms and recently evolved lineage- or species-specific proteins remain uncharacterized or often lack experimental validation. In addition, genetic variants may alter previously known DNA-binding proteins, leading to loss of binding ability. To address this gap, various computational tools have been developed to predict DNA-binding proteins from protein sequences or structures. Yet, their real-world utility in biological research remains uncertain. To evaluate their effectiveness, we assessed the availability and predictive performance of existing tools using five real-world case studies. We found that most tools were web-based, offering accessibility to researchers without computational expertise. However, many suffered from poor maintenance, including frequent server connection problems, input errors, and long processing times. Among the ten tools that were functional and practical, we found that prediction scores often failed to reflect incorrect outputs, and multiple methods frequently produced the same erroneous predictions. Overall, even a small number of misclassifications can significantly distort biological interpretation, indicating that current DNA-binding prediction tools are not yet sufficiently reliable for empirical research.</p>","PeriodicalId":14156,"journal":{"name":"International Journal of Molecular Sciences","volume":"26 19","pages":""},"PeriodicalIF":4.9000,"publicationDate":"2025-10-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12524727/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Molecular Sciences","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.3390/ijms26199785","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
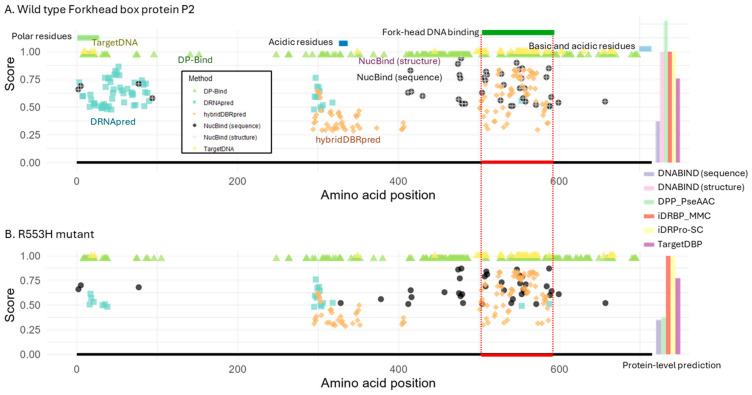
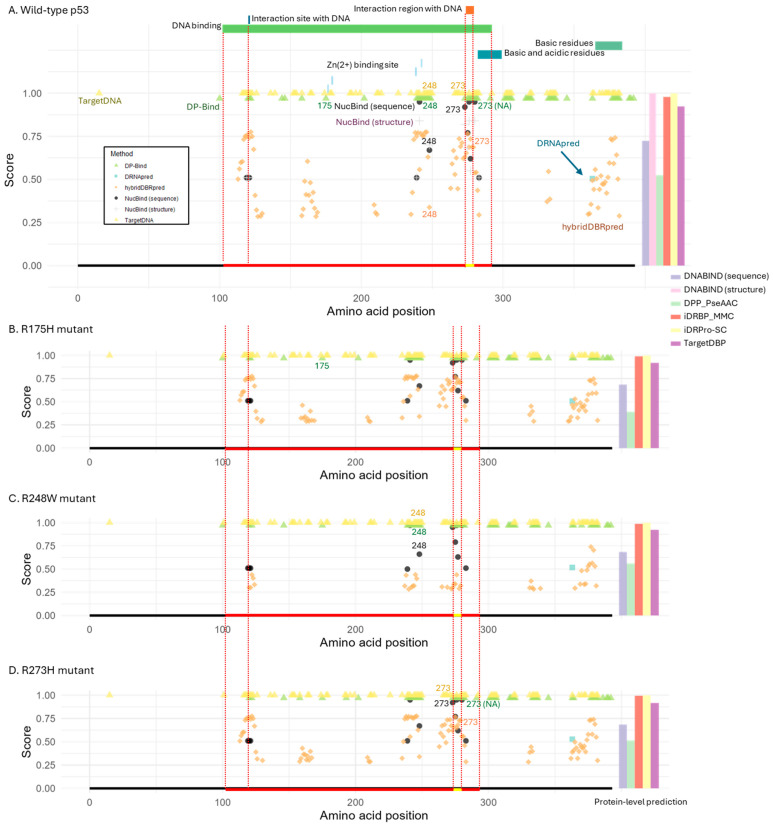
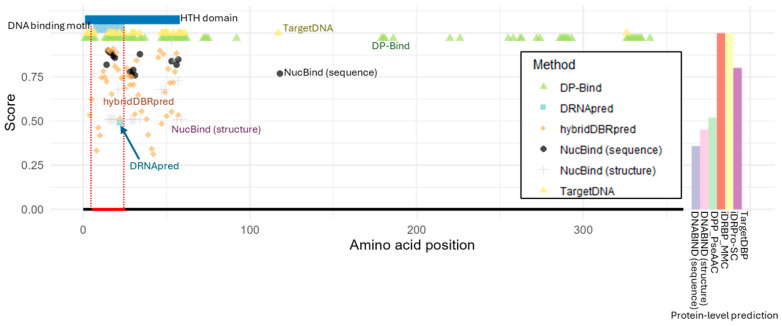
DNA binding proteins play a crucial role in regulating gene expression, DNA replication, and chromatin organization. While many DNA-binding proteins have been identified, many unique DNA-binding proteins in non-model organisms and recently evolved lineage- or species-specific proteins remain uncharacterized or often lack experimental validation. In addition, genetic variants may alter previously known DNA-binding proteins, leading to loss of binding ability. To address this gap, various computational tools have been developed to predict DNA-binding proteins from protein sequences or structures. Yet, their real-world utility in biological research remains uncertain. To evaluate their effectiveness, we assessed the availability and predictive performance of existing tools using five real-world case studies. We found that most tools were web-based, offering accessibility to researchers without computational expertise. However, many suffered from poor maintenance, including frequent server connection problems, input errors, and long processing times. Among the ten tools that were functional and practical, we found that prediction scores often failed to reflect incorrect outputs, and multiple methods frequently produced the same erroneous predictions. Overall, even a small number of misclassifications can significantly distort biological interpretation, indicating that current DNA-binding prediction tools are not yet sufficiently reliable for empirical research.
期刊介绍:
The International Journal of Molecular Sciences (ISSN 1422-0067) provides an advanced forum for chemistry, molecular physics (chemical physics and physical chemistry) and molecular biology. It publishes research articles, reviews, communications and short notes. Our aim is to encourage scientists to publish their theoretical and experimental results in as much detail as possible. Therefore, there is no restriction on the length of the papers or the number of electronics supplementary files. For articles with computational results, the full experimental details must be provided so that the results can be reproduced. Electronic files regarding the full details of the calculation and experimental procedure, if unable to be published in a normal way, can be deposited as supplementary material (including animated pictures, videos, interactive Excel sheets, software executables and others).

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


