Machine learning assisted chitin Extraction: Source and yield prediction from crustacean biomass using deep eutectic solvents
IF 4.9
3区 医学
Q1 PHARMACOLOGY & PHARMACY
Journal of Drug Delivery Science and Technology
Pub Date : 2025-09-19
DOI:10.1016/j.jddst.2025.107548
引用次数: 0
Abstract
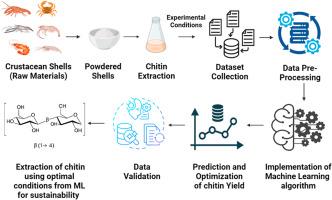
Chitin is the primary polymer after cellulose found in the crustacean shells, insects, and fungi. In recent years, extracting chitin from crustacean shells has garnered attention as a means to convert waste into valuable resources, given its promising applications in various fields. While several methods have been employed to recover chitin, emerging green solvents such as deep eutectic solvents (DES) are increasingly favored to address the challenges posed by traditional chemical, enzymatic, and biological approaches. Chitin extraction efficiency is governed by multiple interdependent factors with complex, non-linear interactions, making conventional trial-and-error optimization both time-consuming and inefficient. These challenges highlight the need for advanced approaches, such as machine learning, to accurately model and optimize the process. Recognized for its reliability and adaptability, machine learning offers an effective approach to modeling the complex, non-linear interactions among process variables in chitin extraction, thereby enabling precise yield prediction and process optimization. The present work proposes a machine learning approach designed to accurately estimate chitin yield and optimize the key parameters governing its extraction. Experimental datasets from chitin extraction trials were used to train and evaluate multiple ML algorithms. Key process variables were treated as input features, with chitin yield as the output target. Among the models tested, XGBoost and Decision Tree achieved the highest predictive accuracy (R2 = 0.99) with minimal root mean square error (RMSE) and mean absolute error (MAE) values. Model-driven optimization was then employed to identify the most favorable combination of process variables. Experimental extractions conducted under the predicted optimal conditions produced chitin yields closely matching the model forecasts, confirming high prediction accuracy. This research demonstrates that machine learning can serve as a cost-effective, efficient method for predicting chitin yield and paves the way for addressing complex issues involving large datasets. Further, the method offers a scalable strategy for enhancing biopolymer recovery and overcoming the multifaceted challenges posed by extensive datasets in sustainable materials research.
机器学习辅助甲壳素提取:利用深共晶溶剂从甲壳类生物质中提取来源和产率预测
几丁质是甲壳类动物、昆虫和真菌中除纤维素之外的主要聚合物。近年来,从甲壳类动物壳中提取甲壳素作为一种将废物转化为有价值资源的手段受到了广泛关注,在各个领域都有广阔的应用前景。虽然有几种方法被用于回收几丁质,但新兴的绿色溶剂,如深共晶溶剂(DES)越来越受到青睐,以解决传统化学,酶和生物方法带来的挑战。甲壳素的提取效率受多个相互依赖的因素的影响,这些因素具有复杂的非线性相互作用,使得传统的试错优化既耗时又低效。这些挑战凸显了对机器学习等先进方法的需求,以准确地建模和优化流程。机器学习因其可靠性和适应性而得到认可,为几丁质提取过程中复杂的非线性相互作用建模提供了有效的方法,从而实现了精确的收率预测和工艺优化。本研究提出了一种机器学习方法,旨在准确估计甲壳素的产量并优化其提取的关键参数。几丁质提取试验的实验数据集用于训练和评估多种机器学习算法。将关键工艺变量作为输入特征,以甲壳素产率为输出目标。在测试的模型中,XGBoost和Decision Tree以最小的均方根误差(RMSE)和平均绝对误差(MAE)值获得了最高的预测精度(R2 = 0.99)。然后采用模型驱动优化来确定最有利的过程变量组合。在预测的最优条件下进行实验提取,得到的甲壳素产率与模型预测非常吻合,证实了较高的预测精度。这项研究表明,机器学习可以作为一种经济有效的预测甲壳素产量的方法,并为解决涉及大型数据集的复杂问题铺平了道路。此外,该方法为提高生物聚合物回收率和克服可持续材料研究中大量数据集带来的多方面挑战提供了可扩展的策略。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

CiteScore
8.00
自引率
8.00%
发文量
879
审稿时长
94 days
期刊介绍:
The Journal of Drug Delivery Science and Technology is an international journal devoted to drug delivery and pharmaceutical technology. The journal covers all innovative aspects of all pharmaceutical dosage forms and the most advanced research on controlled release, bioavailability and drug absorption, nanomedicines, gene delivery, tissue engineering, etc. Hot topics, related to manufacturing processes and quality control, are also welcomed.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


