Lisa Raithel, Johann Frei, Philippe Thomas, Roland Roller, Pierre Zweigenbaum, Sebastian Möller, Frank Kramer
{"title":"Cross- & multi-lingual medication detection: a transformer-based analysis.","authors":"Lisa Raithel, Johann Frei, Philippe Thomas, Roland Roller, Pierre Zweigenbaum, Sebastian Möller, Frank Kramer","doi":"10.1186/s12911-025-03179-1","DOIUrl":null,"url":null,"abstract":"<p><p>Extracting specific information, such as medication mentions, from large unstructured medical texts can be challenging, especially when no annotated corpus exists in the target language for training. To overcome this, leveraging existing machine learning models and datasets is essential, and since most pre-trained resources are in English, adopting multilingual approaches can help transferring between languages. In this work, we investigate the usage of a multi-lingual transformer model in a multi-lingual and cross-lingual setting to extract drug names from medical texts using named entity recognition in four European languages: German, English, French, and Spanish. We report the scores obtained by cross-lingual transfer with several published datasets after fine-tuning a multi-lingual model, aiming to create empirical evidence on how the transfer of \"medical\" knowledge between languages can be expected to benefit various language pairs. We further perform a qualitative error analysis and find that the performance on all languages achieves competitive levels. Conversely, erroneous prediction artifacts are introduced by annotation inconsistencies, differences in annotation guidelines and vague entity labels in general.</p>","PeriodicalId":9340,"journal":{"name":"BMC Medical Informatics and Decision Making","volume":"25 1","pages":"359"},"PeriodicalIF":3.8000,"publicationDate":"2025-10-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12490045/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMC Medical Informatics and Decision Making","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1186/s12911-025-03179-1","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
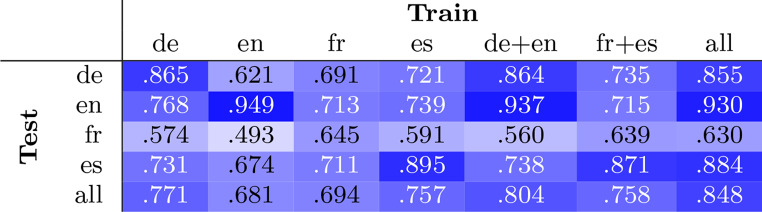
Extracting specific information, such as medication mentions, from large unstructured medical texts can be challenging, especially when no annotated corpus exists in the target language for training. To overcome this, leveraging existing machine learning models and datasets is essential, and since most pre-trained resources are in English, adopting multilingual approaches can help transferring between languages. In this work, we investigate the usage of a multi-lingual transformer model in a multi-lingual and cross-lingual setting to extract drug names from medical texts using named entity recognition in four European languages: German, English, French, and Spanish. We report the scores obtained by cross-lingual transfer with several published datasets after fine-tuning a multi-lingual model, aiming to create empirical evidence on how the transfer of "medical" knowledge between languages can be expected to benefit various language pairs. We further perform a qualitative error analysis and find that the performance on all languages achieves competitive levels. Conversely, erroneous prediction artifacts are introduced by annotation inconsistencies, differences in annotation guidelines and vague entity labels in general.
期刊介绍:
BMC Medical Informatics and Decision Making is an open access journal publishing original peer-reviewed research articles in relation to the design, development, implementation, use, and evaluation of health information technologies and decision-making for human health.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


