Nikhil Joshi, Kawsar Noor, Xi Bai, Marina Forbes, Talisa Ross, Liam Barrett, Richard J B Dobson, Anne G M Schilder, Nishchay Mehta, Watjana Lilaonitkul
{"title":"Automating the extraction of otology symptoms from clinic letters: a methodological study using natural language processing.","authors":"Nikhil Joshi, Kawsar Noor, Xi Bai, Marina Forbes, Talisa Ross, Liam Barrett, Richard J B Dobson, Anne G M Schilder, Nishchay Mehta, Watjana Lilaonitkul","doi":"10.1186/s12911-025-03180-8","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Most healthcare data is in an unstructured format that requires processing to make it usable for research. Generally, this is done manually, which is both time-consuming and poorly scalable. Natural language processing (NLP) using machine learning offers a method to automate data extraction. In this paper we describe the development of a set of NLP models to extract and contextualise otology symptoms from free text documents.</p><p><strong>Methods: </strong>A dataset of 1,148 otology clinic letters written between 2009 - 2011, from a London NHS hospital, were manually annotated and used to train a hybrid dictionary and machine learning NLP model to identify six key otological symptoms: hearing loss, impairment of balance, otalgia, otorrhoea, tinnitus and vertigo. Subsequently, a set of Bidirectional-Long-Short-Term-Memory (Bi-LSTM) models were trained to extract contextual information for each symptom, for example, defining the laterality of the ear affected.</p><p><strong>Results: </strong>There were 1,197 symptom annotations and 2,861 contextual annotations with 24% of patients presenting with hearing loss. The symptom extraction model achieved a macro F1 score of 0.73. The Bi-LSTM models achieved a mean macro F1 score of 0.69 for the contextualisation tasks.</p><p><strong>Conclusion: </strong>NLP models for symptom extraction and contextualisation were successfully created and shown to perform well on real life data. Refinement is needed to produce models that can run without manual review. Downstream applications for these models include deep semantic searching in electronic health records, cohort identification for clinical trials and facilitating research into hearing loss phenotypes. Further testing of the external validity of the developed models is required.</p>","PeriodicalId":9340,"journal":{"name":"BMC Medical Informatics and Decision Making","volume":"25 1","pages":"353"},"PeriodicalIF":3.8000,"publicationDate":"2025-09-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12482202/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMC Medical Informatics and Decision Making","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1186/s12911-025-03180-8","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Most healthcare data is in an unstructured format that requires processing to make it usable for research. Generally, this is done manually, which is both time-consuming and poorly scalable. Natural language processing (NLP) using machine learning offers a method to automate data extraction. In this paper we describe the development of a set of NLP models to extract and contextualise otology symptoms from free text documents.
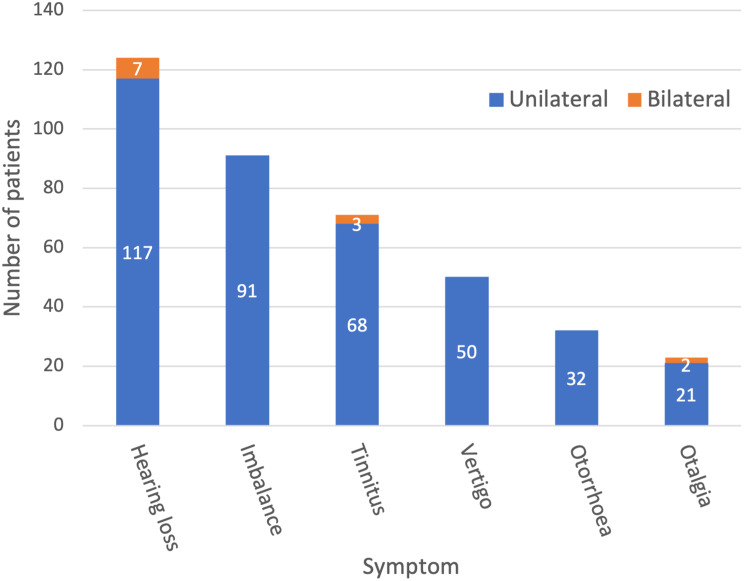
Methods: A dataset of 1,148 otology clinic letters written between 2009 - 2011, from a London NHS hospital, were manually annotated and used to train a hybrid dictionary and machine learning NLP model to identify six key otological symptoms: hearing loss, impairment of balance, otalgia, otorrhoea, tinnitus and vertigo. Subsequently, a set of Bidirectional-Long-Short-Term-Memory (Bi-LSTM) models were trained to extract contextual information for each symptom, for example, defining the laterality of the ear affected.
Results: There were 1,197 symptom annotations and 2,861 contextual annotations with 24% of patients presenting with hearing loss. The symptom extraction model achieved a macro F1 score of 0.73. The Bi-LSTM models achieved a mean macro F1 score of 0.69 for the contextualisation tasks.
Conclusion: NLP models for symptom extraction and contextualisation were successfully created and shown to perform well on real life data. Refinement is needed to produce models that can run without manual review. Downstream applications for these models include deep semantic searching in electronic health records, cohort identification for clinical trials and facilitating research into hearing loss phenotypes. Further testing of the external validity of the developed models is required.
期刊介绍:
BMC Medical Informatics and Decision Making is an open access journal publishing original peer-reviewed research articles in relation to the design, development, implementation, use, and evaluation of health information technologies and decision-making for human health.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


