Aleyna Warner, Jeffrey LeDue, Yutong Cao, Joseph Tham, Timothy H Murphy
{"title":"Synthetic patient and interview transcript creator: an essential tool for LLMs in mental health.","authors":"Aleyna Warner, Jeffrey LeDue, Yutong Cao, Joseph Tham, Timothy H Murphy","doi":"10.3389/fdgth.2025.1625444","DOIUrl":null,"url":null,"abstract":"<p><p>Developing high-quality training data is essential for tailoring large language models (LLMs) to specialized applications like mental health. To address privacy and legal constraints associated with real patient data, we designed a synthetic patient and interview generation framework that can be tailored to regional patient demographics. This system employs two locally run instances of Llama 3.3:70B: one as the interviewer and the other as the patient. These models produce contextually rich interview transcripts, structured by a customizable question bank, with lexical diversity similar to normal human conversation. We calculate median Distinct-1 scores of 0.44 and 0.33 for the patient and interview assistant model outputs respectively compared to 0.50 ± 0.11 as the average for 10,000 episodes of a radio program dialog. Central to this approach is the patient generation process, which begins with a locally run Llama 3.3:70B model. Given the full question bank, the model generates a detailed profile template, combining predefined variables (e.g., demographic data or specific conditions) with LLM-generated content to fill in contextual details. This hybrid method ensures that each patient profile is both diverse and realistic, providing a strong foundation for generating dynamic interactions. Demographic distributions of generated patient profiles were not significantly different from real-world population data and exhibited expected variability. Additionally, for the patient profiles we assessed LLM metrics and found an average Distinct-1 score of 0.8 (max = 1) indicating diverse word usage. By integrating detailed patient generation with dynamic interviewing, the framework produces synthetic datasets that may aid the adoption and deployment of LLMs in mental health settings.</p>","PeriodicalId":73078,"journal":{"name":"Frontiers in digital health","volume":"7 ","pages":"1625444"},"PeriodicalIF":3.2000,"publicationDate":"2025-09-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12460306/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fdgth.2025.1625444","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
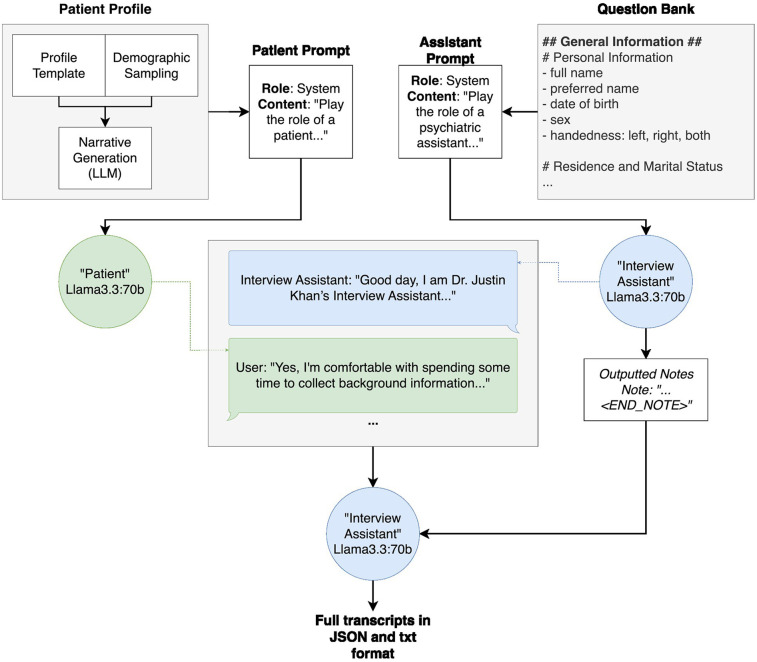
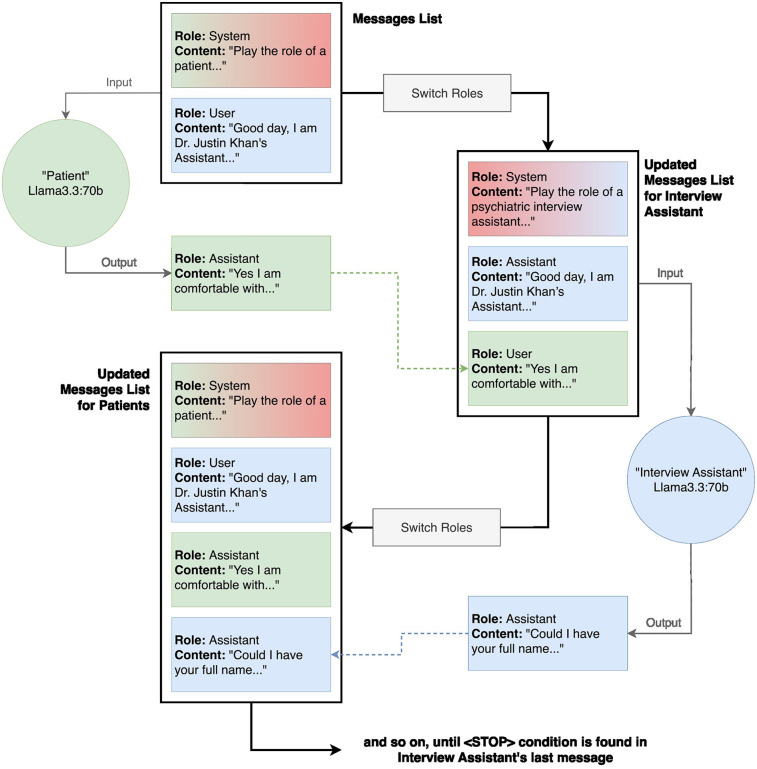
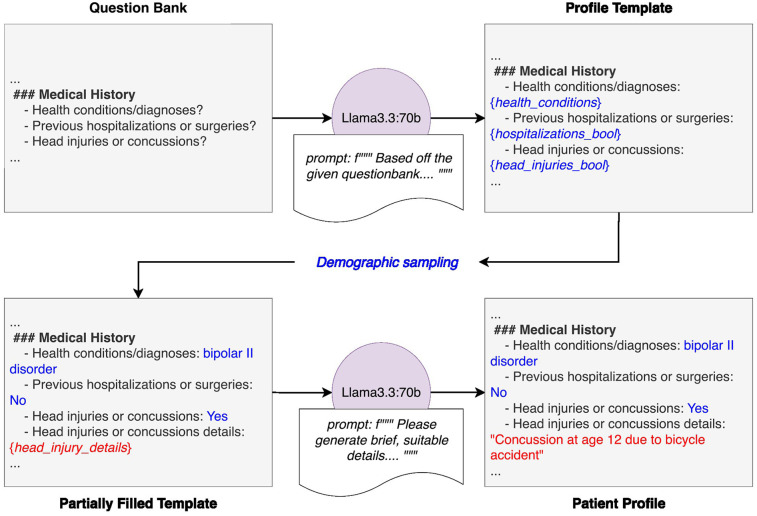
Developing high-quality training data is essential for tailoring large language models (LLMs) to specialized applications like mental health. To address privacy and legal constraints associated with real patient data, we designed a synthetic patient and interview generation framework that can be tailored to regional patient demographics. This system employs two locally run instances of Llama 3.3:70B: one as the interviewer and the other as the patient. These models produce contextually rich interview transcripts, structured by a customizable question bank, with lexical diversity similar to normal human conversation. We calculate median Distinct-1 scores of 0.44 and 0.33 for the patient and interview assistant model outputs respectively compared to 0.50 ± 0.11 as the average for 10,000 episodes of a radio program dialog. Central to this approach is the patient generation process, which begins with a locally run Llama 3.3:70B model. Given the full question bank, the model generates a detailed profile template, combining predefined variables (e.g., demographic data or specific conditions) with LLM-generated content to fill in contextual details. This hybrid method ensures that each patient profile is both diverse and realistic, providing a strong foundation for generating dynamic interactions. Demographic distributions of generated patient profiles were not significantly different from real-world population data and exhibited expected variability. Additionally, for the patient profiles we assessed LLM metrics and found an average Distinct-1 score of 0.8 (max = 1) indicating diverse word usage. By integrating detailed patient generation with dynamic interviewing, the framework produces synthetic datasets that may aid the adoption and deployment of LLMs in mental health settings.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


