{"title":"Clinical applications and limitations of large language models in nephrology: a systematic review.","authors":"Zoe Unger, Shelly Soffer, Orly Efros, Lili Chan, Eyal Klang, Girish N Nadkarni","doi":"10.1093/ckj/sfaf243","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Large language models (LLMs) have emerged as potential tools in healthcare. This systematic review evaluates the applications of text-generative conversational LLMs in nephrology, with particular attention to their reported advantages and limitations.</p><p><strong>Methods: </strong>A systematic search was performed in PubMed, Web of Science, Embase and the Cochrane Library in accordance with the Preferred Reporting Items for Systematic Reviews and Meta-Analyses guidelines. Eligible studies assessed LLM applications in nephrology. PROSPERO registration number CRD42024550169.</p><p><strong>Results: </strong>Of 1070 records screened, 23 studies met inclusion criteria, addressing four clinical applications in nephrology. In patient education (<i>n</i> = 13), GPT-4 improved the readability of kidney donation information from a 10th to a 4th grade level (9.6 ± 1.9 to 4.30 ± 1.71) and Gemini provided the most accurate answers to chronic kidney disease questions (Global Quality Score 3.46 ± 0.55). Regarding workflow optimization (<i>n</i> = 7), GPT-4 achieved high accuracy (90-94%) in managing continuous renal replacement therapy alarms and improved diagnosis of diabetes insipidus using chain-of-thought and retrieval-augmented prompting. In renal dietary guidance (<i>n</i> = 2), Bard AI led in classifying phosphorus and oxalate content of foods (100% and 84%), while GPT-4 and Bing Chat were most accurate for potassium classification (81%). For laboratory data interpretation (<i>n</i> = 1), Copilot significantly outperformed ChatGPT and Gemini in simulated nephrology datasets (median scores 5/5 compared with 4/5 and 4/5; <i>P</i> < .01). TRIPOD-LLM assessment revealed frequent omissions in data handling, prompting strategies and transparency.</p><p><strong>Conclusions: </strong>While LLMs may enhance various aspects of nephrology practice, their widespread adoption remains premature. Input-quality dependence and limited external validation restrict generalizability. Further research is needed to confirm their real-world feasibility and ensure safe clinical integration.</p>","PeriodicalId":10435,"journal":{"name":"Clinical Kidney Journal","volume":"18 9","pages":"sfaf243"},"PeriodicalIF":4.6000,"publicationDate":"2025-09-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12461145/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Clinical Kidney Journal","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1093/ckj/sfaf243","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/9/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"UROLOGY & NEPHROLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Large language models (LLMs) have emerged as potential tools in healthcare. This systematic review evaluates the applications of text-generative conversational LLMs in nephrology, with particular attention to their reported advantages and limitations.
Methods: A systematic search was performed in PubMed, Web of Science, Embase and the Cochrane Library in accordance with the Preferred Reporting Items for Systematic Reviews and Meta-Analyses guidelines. Eligible studies assessed LLM applications in nephrology. PROSPERO registration number CRD42024550169.
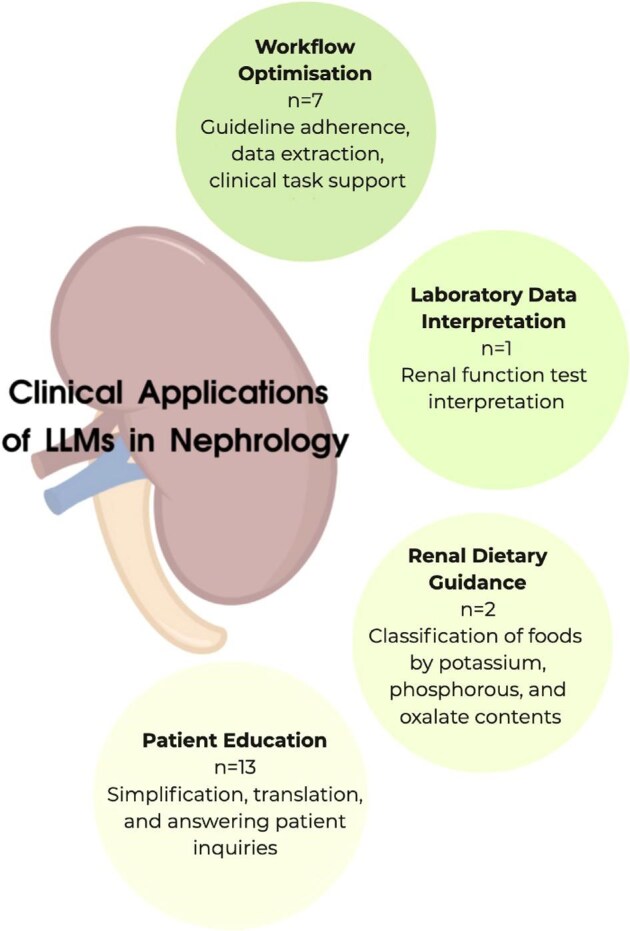
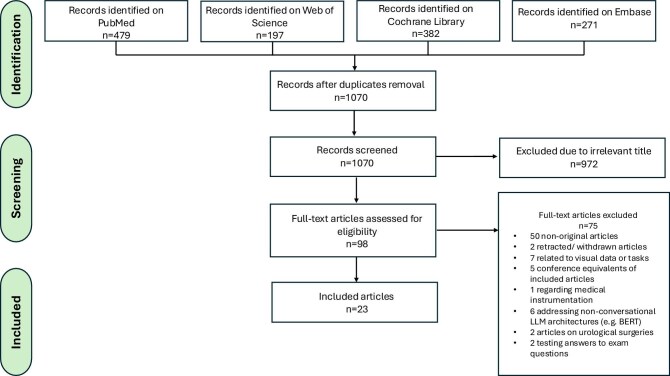
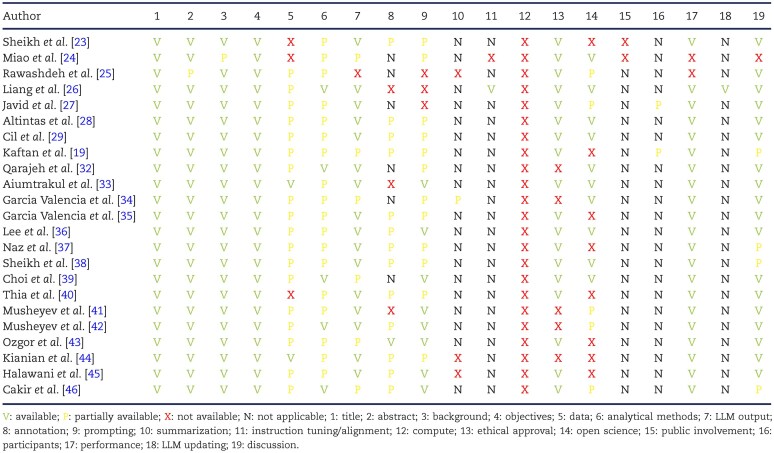
Results: Of 1070 records screened, 23 studies met inclusion criteria, addressing four clinical applications in nephrology. In patient education (n = 13), GPT-4 improved the readability of kidney donation information from a 10th to a 4th grade level (9.6 ± 1.9 to 4.30 ± 1.71) and Gemini provided the most accurate answers to chronic kidney disease questions (Global Quality Score 3.46 ± 0.55). Regarding workflow optimization (n = 7), GPT-4 achieved high accuracy (90-94%) in managing continuous renal replacement therapy alarms and improved diagnosis of diabetes insipidus using chain-of-thought and retrieval-augmented prompting. In renal dietary guidance (n = 2), Bard AI led in classifying phosphorus and oxalate content of foods (100% and 84%), while GPT-4 and Bing Chat were most accurate for potassium classification (81%). For laboratory data interpretation (n = 1), Copilot significantly outperformed ChatGPT and Gemini in simulated nephrology datasets (median scores 5/5 compared with 4/5 and 4/5; P < .01). TRIPOD-LLM assessment revealed frequent omissions in data handling, prompting strategies and transparency.
Conclusions: While LLMs may enhance various aspects of nephrology practice, their widespread adoption remains premature. Input-quality dependence and limited external validation restrict generalizability. Further research is needed to confirm their real-world feasibility and ensure safe clinical integration.
期刊介绍:
About the Journal
Clinical Kidney Journal: Clinical and Translational Nephrology (ckj), an official journal of the ERA-EDTA (European Renal Association-European Dialysis and Transplant Association), is a fully open access, online only journal publishing bimonthly. The journal is an essential educational and training resource integrating clinical, translational and educational research into clinical practice. ckj aims to contribute to a translational research culture among nephrologists and kidney pathologists that helps close the gap between basic researchers and practicing clinicians and promote sorely needed innovation in the Nephrology field. All research articles in this journal have undergone peer review.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


