The incremental value of unstructured data via natural language processing in machine learning-based COVID-19 mortality prediction: a comparative study.
{"title":"The incremental value of unstructured data via natural language processing in machine learning-based COVID-19 mortality prediction: a comparative study.","authors":"Rildo Pinto da Silva, Antonio Pazin-Filho","doi":"10.1186/s12911-025-03178-2","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>While it is advocated that the use of unstructured data extracted from medical records is important for enhancing machine learning models, few studies have evaluated whether this occurs. A retrospective, head-to-head comparative study was conducted to evaluate machine learning models for in-hospital mortality prediction. The study assessed and quantified the potential performance improvement resulting from the inclusion of unstructured data.</p><p><strong>Methods: </strong>Hospitalizations of patients with a confirmed COVID-19 diagnosis at a tertiary teaching hospital specialized in emergency care were selected (n = 844). For the models with structured data, 21 variables were selected from laboratory tests and patient monitoring. For the hybrid models, an additional 21 clinical assertions (e.g., \"has_symptom affirmed dyspnea\") were included. Six models with the best discriminative performance out of 11 trained and validated were selected for the testing phase. The most representative variables were evaluated using an explainable artificial intelligence model.</p><p><strong>Results: </strong>The random forest model demonstrated the highest performance, achieving an area under the receiver operating characteristic curve (AUC ROC) of 0.9260, an increase from 0.9170 when using only structured data. The inclusion of unstructured data also improved sensitivity from 0.8108 to 0.8378 while specificity was maintained at 0.8667. However, these performance improvements were not found to be statistically significant different from models with only structured data.</p><p><strong>Conclusion: </strong>The study concluded that the inclusion of unstructured data did not increase the predictive power of machine learning models for COVID-19 mortality. It was also determined that human involvement is crucial for implementation, specifically for validating natural language processing (NLP) outputs and tailoring the selection of unstructured features, given the inherent challenges in processing such data.</p><p><strong>Clinical trial number: </strong>Not applicable.</p>","PeriodicalId":9340,"journal":{"name":"BMC Medical Informatics and Decision Making","volume":"25 1","pages":"333"},"PeriodicalIF":3.8000,"publicationDate":"2025-09-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12465758/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMC Medical Informatics and Decision Making","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1186/s12911-025-03178-2","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: While it is advocated that the use of unstructured data extracted from medical records is important for enhancing machine learning models, few studies have evaluated whether this occurs. A retrospective, head-to-head comparative study was conducted to evaluate machine learning models for in-hospital mortality prediction. The study assessed and quantified the potential performance improvement resulting from the inclusion of unstructured data.
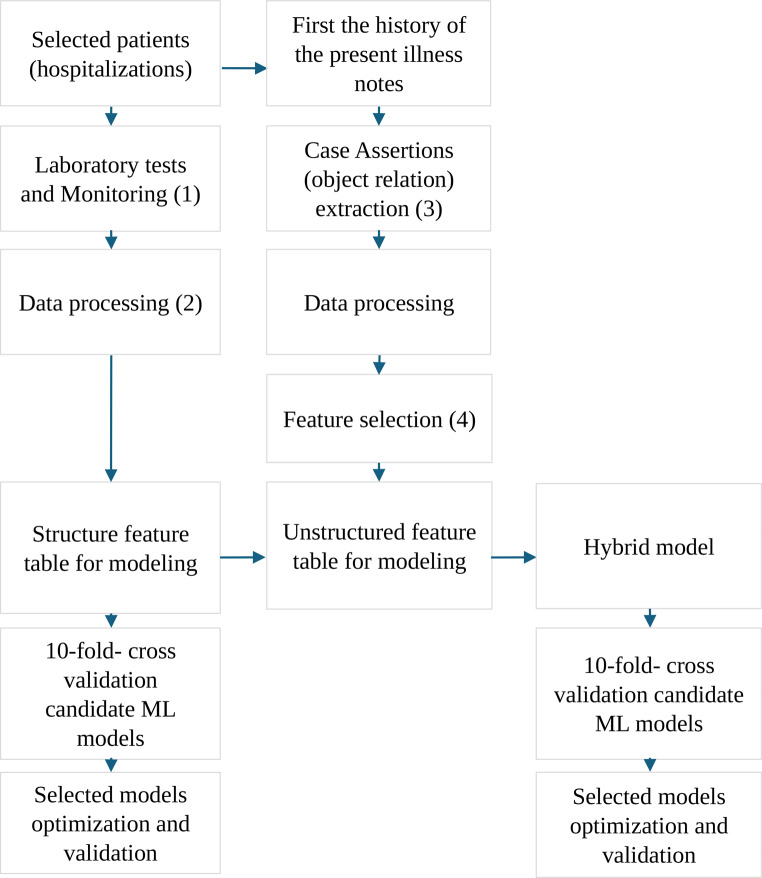
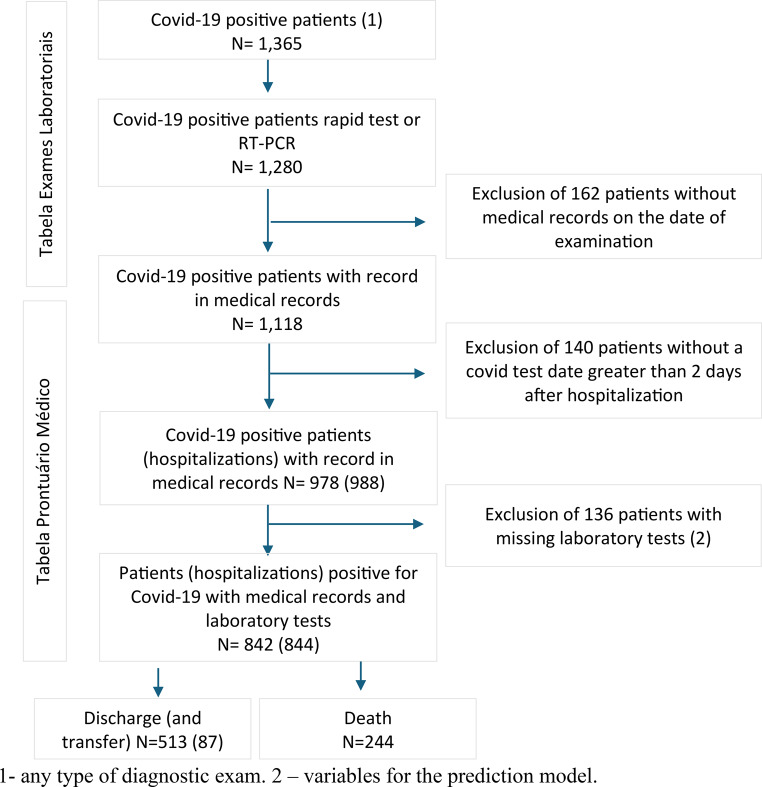
Methods: Hospitalizations of patients with a confirmed COVID-19 diagnosis at a tertiary teaching hospital specialized in emergency care were selected (n = 844). For the models with structured data, 21 variables were selected from laboratory tests and patient monitoring. For the hybrid models, an additional 21 clinical assertions (e.g., "has_symptom affirmed dyspnea") were included. Six models with the best discriminative performance out of 11 trained and validated were selected for the testing phase. The most representative variables were evaluated using an explainable artificial intelligence model.
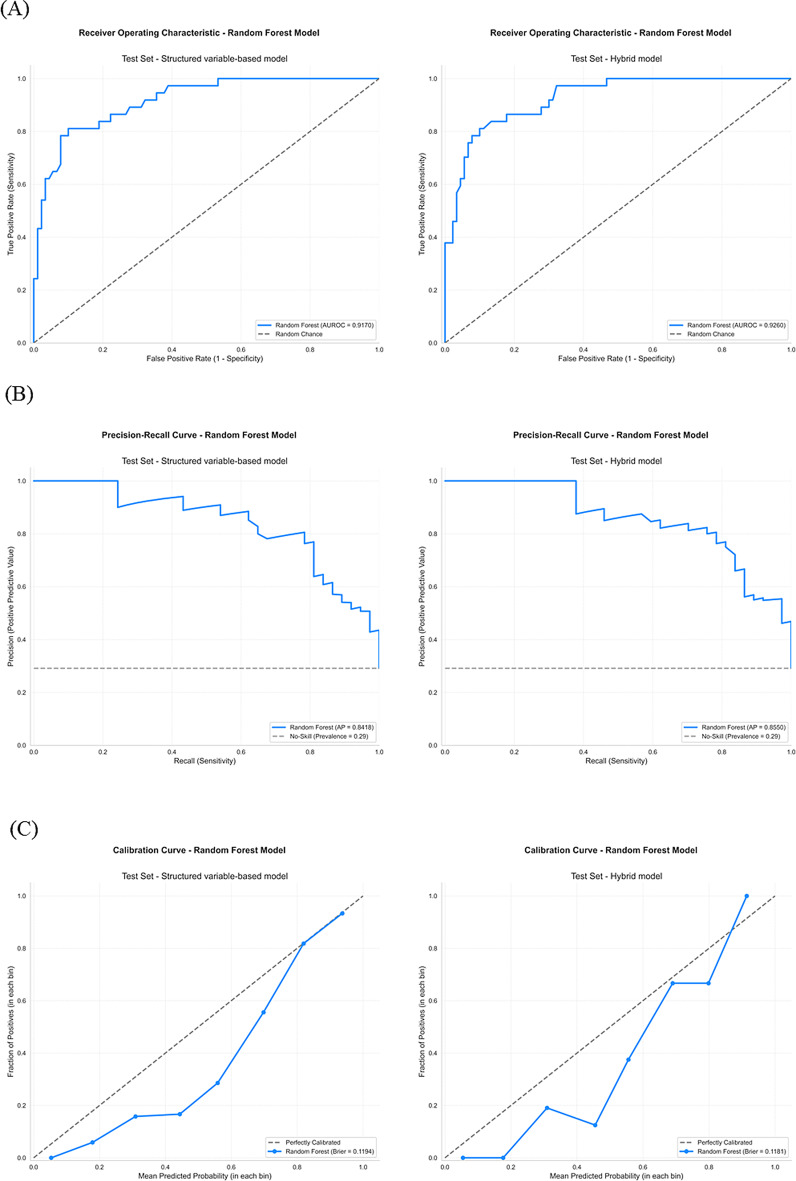
Results: The random forest model demonstrated the highest performance, achieving an area under the receiver operating characteristic curve (AUC ROC) of 0.9260, an increase from 0.9170 when using only structured data. The inclusion of unstructured data also improved sensitivity from 0.8108 to 0.8378 while specificity was maintained at 0.8667. However, these performance improvements were not found to be statistically significant different from models with only structured data.
Conclusion: The study concluded that the inclusion of unstructured data did not increase the predictive power of machine learning models for COVID-19 mortality. It was also determined that human involvement is crucial for implementation, specifically for validating natural language processing (NLP) outputs and tailoring the selection of unstructured features, given the inherent challenges in processing such data.
期刊介绍:
BMC Medical Informatics and Decision Making is an open access journal publishing original peer-reviewed research articles in relation to the design, development, implementation, use, and evaluation of health information technologies and decision-making for human health.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


