Xueqi Wang, Jianhua Guo, Tao Zhang, Huajun Lu, Dandan Zhou, Haitao Zhang, Xuebin Wang
{"title":"Evaluating the performance of ChatGPT in clinical multidisciplinary treatment: a retrospective study.","authors":"Xueqi Wang, Jianhua Guo, Tao Zhang, Huajun Lu, Dandan Zhou, Haitao Zhang, Xuebin Wang","doi":"10.1186/s12911-025-03181-7","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Multidisciplinary treatment (MDT) consultations are essential for managing complex patients. However, resource and time constraints can limit their quality. Large language models (LLMs) have shown potential in assisting clinical decision-making, but their performance in complex MDT scenarios remains unclear. This study aims to evaluate the quality of MDT recommendations generated by ChatGPT compared to those provided by physicians.</p><p><strong>Methods: </strong>Clinical data from 64 patient cases were retrospectively included in the study. ChatGPT was asked to provide specific MDT recommendations. 2 experienced physicians evaluated and scored the responses in a blinded manner across 5 aspects: comprehensiveness, accuracy, feasibility, safety, and efficiency, each assessed by 2 questions.</p><p><strong>Results: </strong>The median overall score for ChatGPT was 41.0 out of 50.0, which was lower than the MDT physicians' median score of 43.5 (p = 0.001). Compared to the MDT physicians' responses, ChatGPT excelled in comprehensiveness (p < 0.001) but fell short in accuracy (p < 0.001), feasibility (p < 0.001), and efficiency (p = 0.003). Analysis of specific questions revealed that ChatGPT lacked the ability to reason through the etiologies of complex cases.</p><p><strong>Conclusion: </strong>This study indicates that ChatGPT has potential in clinical MDT applications, particularly in demonstrating more comprehensive consideration of clinical factors. However, ChatGPT still has deficiencies in accuracy, which could lead to incorrect healthcare decisions. Therefore, further development and clinical validation of LLMs are necessary. Recognizing the current limitations of LLMs, it is essential to use them with caution in clinical practice.</p><p><strong>Trial registration: </strong>Not applicable to the present retrospective study. For transparency, a related prospective extension is registered at ChiCTR (ChiCTR2400088563; registered on 21 August 2024).</p>","PeriodicalId":9340,"journal":{"name":"BMC Medical Informatics and Decision Making","volume":"25 1","pages":"340"},"PeriodicalIF":3.8000,"publicationDate":"2025-09-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12465737/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMC Medical Informatics and Decision Making","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1186/s12911-025-03181-7","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Multidisciplinary treatment (MDT) consultations are essential for managing complex patients. However, resource and time constraints can limit their quality. Large language models (LLMs) have shown potential in assisting clinical decision-making, but their performance in complex MDT scenarios remains unclear. This study aims to evaluate the quality of MDT recommendations generated by ChatGPT compared to those provided by physicians.
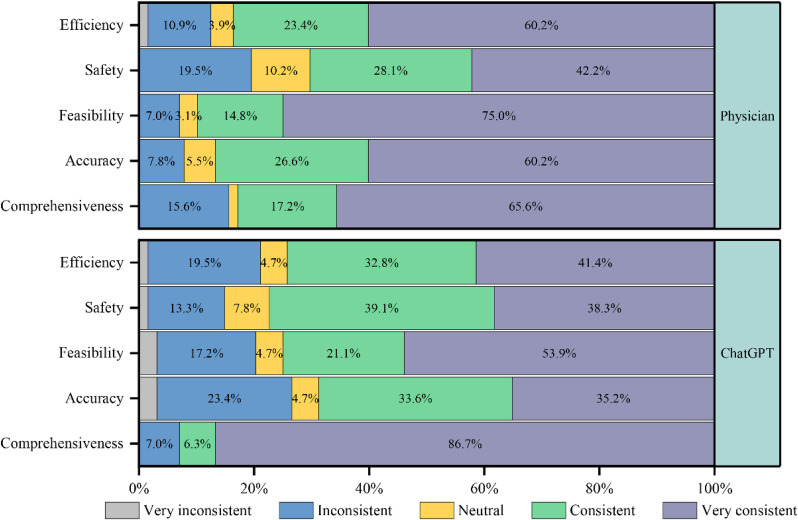
Methods: Clinical data from 64 patient cases were retrospectively included in the study. ChatGPT was asked to provide specific MDT recommendations. 2 experienced physicians evaluated and scored the responses in a blinded manner across 5 aspects: comprehensiveness, accuracy, feasibility, safety, and efficiency, each assessed by 2 questions.
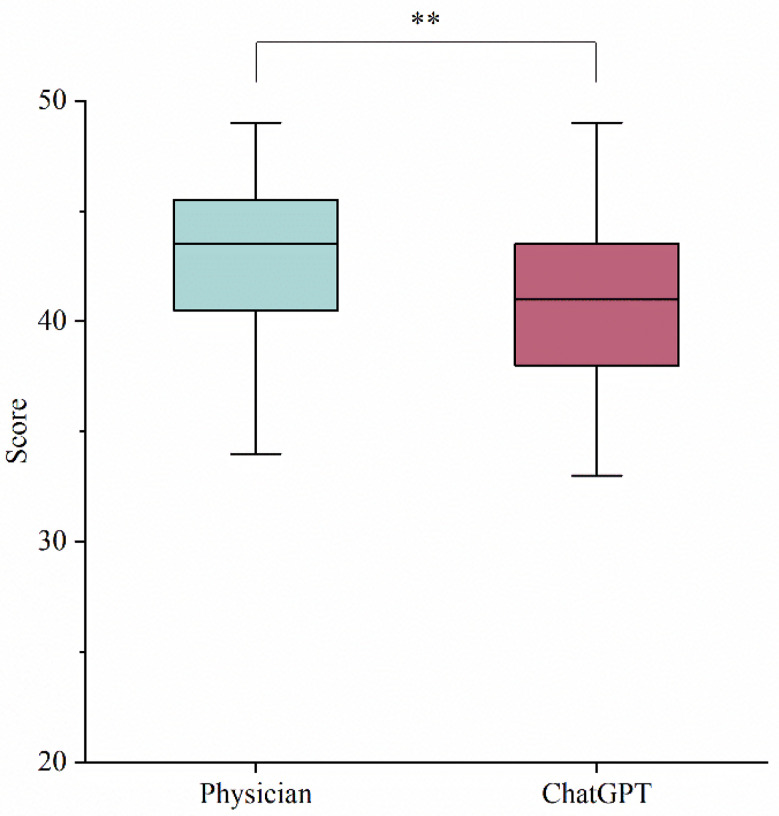
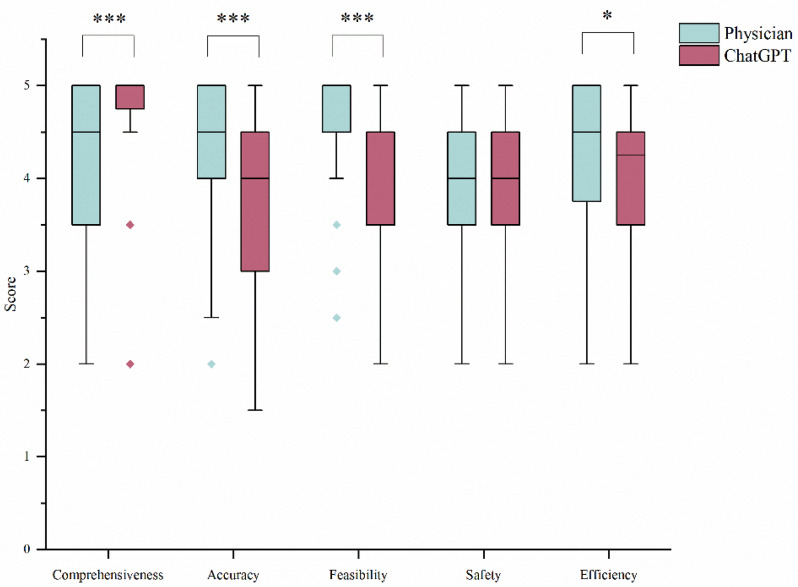
Results: The median overall score for ChatGPT was 41.0 out of 50.0, which was lower than the MDT physicians' median score of 43.5 (p = 0.001). Compared to the MDT physicians' responses, ChatGPT excelled in comprehensiveness (p < 0.001) but fell short in accuracy (p < 0.001), feasibility (p < 0.001), and efficiency (p = 0.003). Analysis of specific questions revealed that ChatGPT lacked the ability to reason through the etiologies of complex cases.
Conclusion: This study indicates that ChatGPT has potential in clinical MDT applications, particularly in demonstrating more comprehensive consideration of clinical factors. However, ChatGPT still has deficiencies in accuracy, which could lead to incorrect healthcare decisions. Therefore, further development and clinical validation of LLMs are necessary. Recognizing the current limitations of LLMs, it is essential to use them with caution in clinical practice.
Trial registration: Not applicable to the present retrospective study. For transparency, a related prospective extension is registered at ChiCTR (ChiCTR2400088563; registered on 21 August 2024).
期刊介绍:
BMC Medical Informatics and Decision Making is an open access journal publishing original peer-reviewed research articles in relation to the design, development, implementation, use, and evaluation of health information technologies and decision-making for human health.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


