Nii Adjetey Tawiah, Emmanuel A Appiah, Felisha White
{"title":"Predicting Adverse Childhood Experiences from Family Environment Factors: A Machine Learning Approach.","authors":"Nii Adjetey Tawiah, Emmanuel A Appiah, Felisha White","doi":"10.3390/bs15091216","DOIUrl":null,"url":null,"abstract":"<p><p>Adverse childhood experiences (ACEs) are associated with profound long-term health and developmental consequences. However, current identification strategies are largely reactive, often missing opportunities for early intervention. Therefore, the potential of machine learning to proactively identify children at risk of ACE exposure needs to be explored. Using nationally representative data from 63,239 children in the 2018-2020 National Survey of Children's Health (NSCH) after listwise deletion, we trained and validated multiple machine learning models to predict ACE exposure categorized as none, one, or two or more ACEs. Model performance was assessed using accuracy, precision, recall, F1 scores, and area under the curve (AUC) metrics with 5-fold cross-validation. The Random Forest model achieved the highest predictive accuracy (82%) and demonstrated strong performance across ACE categories. Key predictive features included child sex (female), food insufficiency, school absenteeism, quality of parent-child communication, and experiences of bullying. The model yielded high performance in identifying children with no ACEs (F1 = 0.89) and moderate performance for those with multiple ACEs (F1 = 0.64). However, performance for the single ACE category was notably lower (F1 = 0.55), indicating challenges in predicting this intermediate group. These findings suggest that family environment factors can be leveraged to predict ACE exposure with clinically meaningful accuracy, offering a foundation for proactive screening protocols. However, implementation must carefully address systematic selection bias, clinical utility limitations, and ethical considerations regarding predictive modeling of vulnerable children.</p>","PeriodicalId":8742,"journal":{"name":"Behavioral Sciences","volume":"15 9","pages":""},"PeriodicalIF":2.5000,"publicationDate":"2025-09-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12466657/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Behavioral Sciences","FirstCategoryId":"102","ListUrlMain":"https://doi.org/10.3390/bs15091216","RegionNum":3,"RegionCategory":"心理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"PSYCHOLOGY, MULTIDISCIPLINARY","Score":null,"Total":0}
引用次数: 0
Abstract
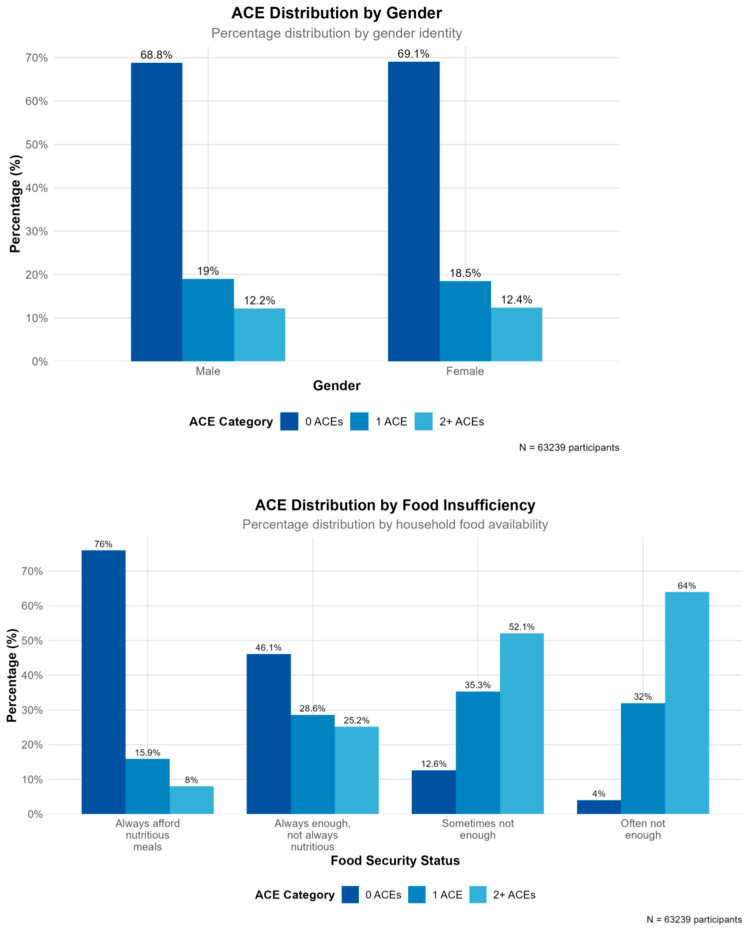
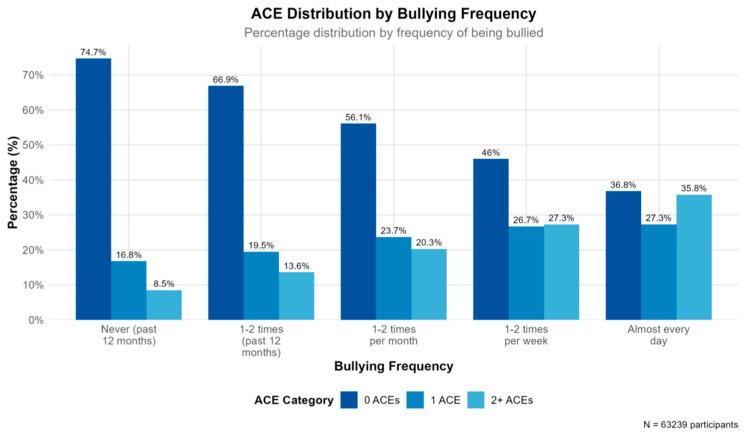
Adverse childhood experiences (ACEs) are associated with profound long-term health and developmental consequences. However, current identification strategies are largely reactive, often missing opportunities for early intervention. Therefore, the potential of machine learning to proactively identify children at risk of ACE exposure needs to be explored. Using nationally representative data from 63,239 children in the 2018-2020 National Survey of Children's Health (NSCH) after listwise deletion, we trained and validated multiple machine learning models to predict ACE exposure categorized as none, one, or two or more ACEs. Model performance was assessed using accuracy, precision, recall, F1 scores, and area under the curve (AUC) metrics with 5-fold cross-validation. The Random Forest model achieved the highest predictive accuracy (82%) and demonstrated strong performance across ACE categories. Key predictive features included child sex (female), food insufficiency, school absenteeism, quality of parent-child communication, and experiences of bullying. The model yielded high performance in identifying children with no ACEs (F1 = 0.89) and moderate performance for those with multiple ACEs (F1 = 0.64). However, performance for the single ACE category was notably lower (F1 = 0.55), indicating challenges in predicting this intermediate group. These findings suggest that family environment factors can be leveraged to predict ACE exposure with clinically meaningful accuracy, offering a foundation for proactive screening protocols. However, implementation must carefully address systematic selection bias, clinical utility limitations, and ethical considerations regarding predictive modeling of vulnerable children.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


