Evaluating a Custom Chatbot in Undergraduate Medical Education: Randomised Crossover Mixed-Methods Evaluation of Performance, Utility, and Perceptions.
Isaac Sung Him Ng, Anthony Siu, Claire Soo Jeong Han, Oscar Sing Him Ho, Johnathan Sun, Anatoliy Markiv, Stuart Knight, Mandeep Gill Sagoo
{"title":"Evaluating a Custom Chatbot in Undergraduate Medical Education: Randomised Crossover Mixed-Methods Evaluation of Performance, Utility, and Perceptions.","authors":"Isaac Sung Him Ng, Anthony Siu, Claire Soo Jeong Han, Oscar Sing Him Ho, Johnathan Sun, Anatoliy Markiv, Stuart Knight, Mandeep Gill Sagoo","doi":"10.3390/bs15091284","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>While LLM chatbots are gaining popularity in medical education, their pedagogical impact remains under-evaluated. This study examined the effects of a domain-specific chatbot on performance, perception, and cognitive engagement among medical students.</p><p><strong>Methods: </strong>Twenty first-year medical students completed two academic tasks using either a custom-built educational chatbot (Lenny AI by qVault) or conventional study methods in a randomised, crossover design. Performance was assessed through Single Best Answer (SBA) questions, while post-task surveys (Likert scales) and focus groups were employed to explore user perceptions. Statistical tests compared performance and perception metrics; qualitative data underwent thematic analysis with independent coding (κ = 0.403-0.633).</p><p><strong>Results: </strong>Participants rated the chatbot significantly higher than conventional resources for ease of use, satisfaction, engagement, perceived quality, and clarity (<i>p</i> < 0.05). Lenny AI use was positively correlated with perceived efficiency and confidence, but showed no significant performance gains. Thematic analysis revealed accelerated factual retrieval but limited support for higher-level cognitive reasoning. Students expressed high functional trust but raised concerns about transparency.</p><p><strong>Conclusions: </strong>The custom chatbot improved usability; effects on deeper learning were not detected within the tasks studied. Future designs should support adaptive scaffolding, transparent sourcing, and critical engagement to improve educational value.</p>","PeriodicalId":8742,"journal":{"name":"Behavioral Sciences","volume":"15 9","pages":""},"PeriodicalIF":2.5000,"publicationDate":"2025-09-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12467370/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Behavioral Sciences","FirstCategoryId":"102","ListUrlMain":"https://doi.org/10.3390/bs15091284","RegionNum":3,"RegionCategory":"心理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"PSYCHOLOGY, MULTIDISCIPLINARY","Score":null,"Total":0}
引用次数: 0
Abstract
Background: While LLM chatbots are gaining popularity in medical education, their pedagogical impact remains under-evaluated. This study examined the effects of a domain-specific chatbot on performance, perception, and cognitive engagement among medical students.
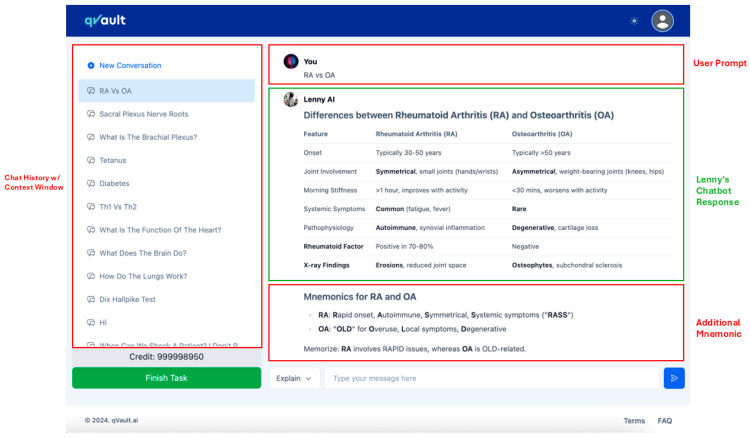
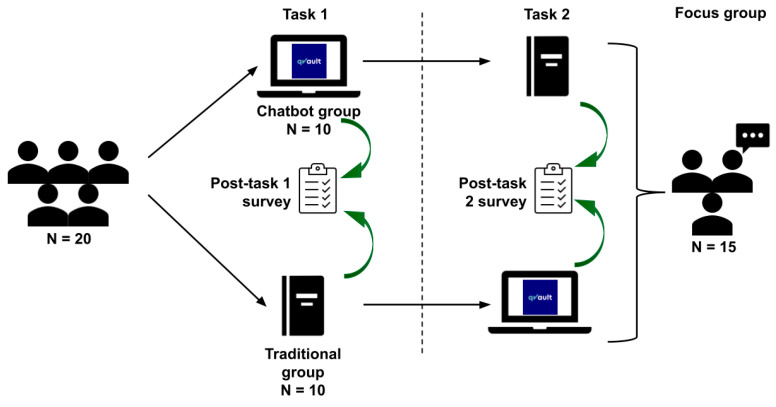
Methods: Twenty first-year medical students completed two academic tasks using either a custom-built educational chatbot (Lenny AI by qVault) or conventional study methods in a randomised, crossover design. Performance was assessed through Single Best Answer (SBA) questions, while post-task surveys (Likert scales) and focus groups were employed to explore user perceptions. Statistical tests compared performance and perception metrics; qualitative data underwent thematic analysis with independent coding (κ = 0.403-0.633).
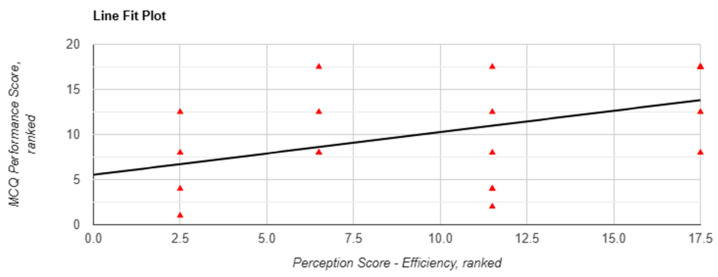
Results: Participants rated the chatbot significantly higher than conventional resources for ease of use, satisfaction, engagement, perceived quality, and clarity (p < 0.05). Lenny AI use was positively correlated with perceived efficiency and confidence, but showed no significant performance gains. Thematic analysis revealed accelerated factual retrieval but limited support for higher-level cognitive reasoning. Students expressed high functional trust but raised concerns about transparency.
Conclusions: The custom chatbot improved usability; effects on deeper learning were not detected within the tasks studied. Future designs should support adaptive scaffolding, transparent sourcing, and critical engagement to improve educational value.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


