{"title":"LSTM-Enhanced TD3 and Behavior Cloning for UAV Trajectory Tracking Control.","authors":"Yuanhang Qi, Jintao Hu, Fujie Wang, Gewen Huang","doi":"10.3390/biomimetics10090591","DOIUrl":null,"url":null,"abstract":"<p><p>Unmanned aerial vehicles (UAVs) often face significant challenges in trajectory tracking within complex dynamic environments, where uncertainties, external disturbances, and nonlinear dynamics hinder accurate and stable control. To address this issue, a bio-inspired deep reinforcement learning (DRL) algorithm is proposed, integrating behavior cloning (BC) and long short-term memory (LSTM) networks. This method can achieve autonomous learning of high-precision control policy without establishing an accurate system dynamics model. Motivated by the memory and prediction functions of biological neural systems, an LSTM module is embedded into the policy network of the Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm. This structure captures temporal state patterns more effectively, enhancing adaptability to trajectory variations and resilience to delays or disturbances. Compared to memoryless networks, the LSTM-based design better replicates biological time-series processing, improving tracking stability and accuracy. In addition, behavior cloning is employed to pre-train the DRL policy using expert demonstrations, mimicking the way animals learn from observation. This biomimetic plausible initialization accelerates convergence by reducing inefficient early-stage exploration. By combining offline imitation with online learning, the TD3-LSTM-BC framework balances expert guidance and adaptive optimization, analogous to innate and experience-based learning in nature. Simulation experimental results confirm the superior robustness and tracking accuracy of the proposed method, demonstrating its potential as a control solution for autonomous UAVs.</p>","PeriodicalId":8907,"journal":{"name":"Biomimetics","volume":"10 9","pages":""},"PeriodicalIF":3.9000,"publicationDate":"2025-09-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12467034/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biomimetics","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.3390/biomimetics10090591","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"ENGINEERING, MULTIDISCIPLINARY","Score":null,"Total":0}
引用次数: 0
Abstract
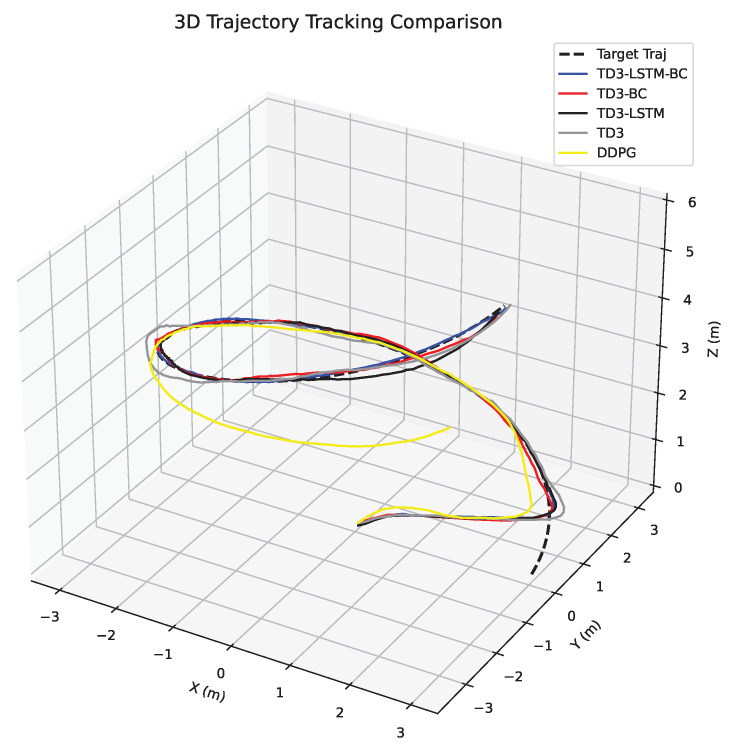
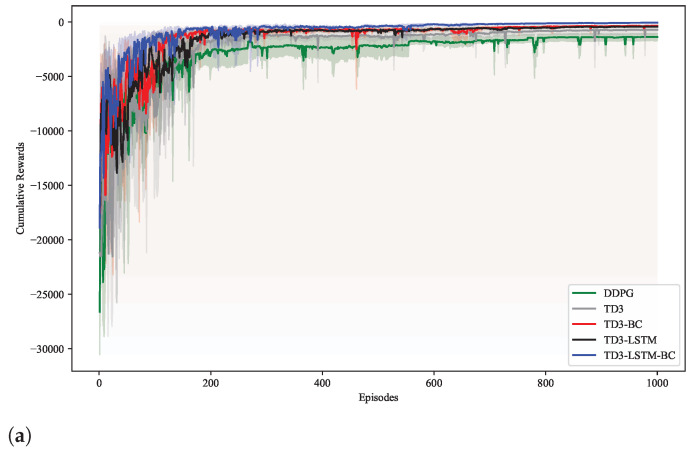
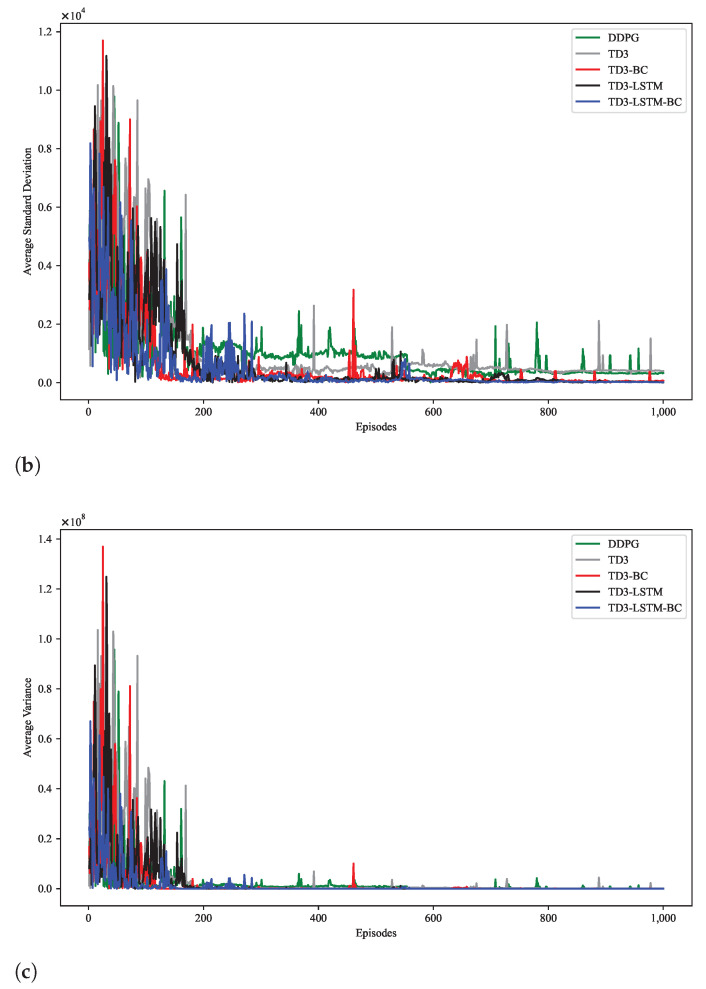
Unmanned aerial vehicles (UAVs) often face significant challenges in trajectory tracking within complex dynamic environments, where uncertainties, external disturbances, and nonlinear dynamics hinder accurate and stable control. To address this issue, a bio-inspired deep reinforcement learning (DRL) algorithm is proposed, integrating behavior cloning (BC) and long short-term memory (LSTM) networks. This method can achieve autonomous learning of high-precision control policy without establishing an accurate system dynamics model. Motivated by the memory and prediction functions of biological neural systems, an LSTM module is embedded into the policy network of the Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm. This structure captures temporal state patterns more effectively, enhancing adaptability to trajectory variations and resilience to delays or disturbances. Compared to memoryless networks, the LSTM-based design better replicates biological time-series processing, improving tracking stability and accuracy. In addition, behavior cloning is employed to pre-train the DRL policy using expert demonstrations, mimicking the way animals learn from observation. This biomimetic plausible initialization accelerates convergence by reducing inefficient early-stage exploration. By combining offline imitation with online learning, the TD3-LSTM-BC framework balances expert guidance and adaptive optimization, analogous to innate and experience-based learning in nature. Simulation experimental results confirm the superior robustness and tracking accuracy of the proposed method, demonstrating its potential as a control solution for autonomous UAVs.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


