Giulia Lorenzoni, Camilla Zanotto, Anna Sordo, Alberto Cipriani, Martina Perazzolo Marra, Francesco Tona, Daniele Gasparini, Dario Gregori
{"title":"Large language models to develop evidence-based strategies for primary and secondary cardiovascular prevention.","authors":"Giulia Lorenzoni, Camilla Zanotto, Anna Sordo, Alberto Cipriani, Martina Perazzolo Marra, Francesco Tona, Daniele Gasparini, Dario Gregori","doi":"10.1093/ehjdh/ztaf085","DOIUrl":null,"url":null,"abstract":"<p><strong>Aims: </strong>Cardiovascular diseases are the leading global cause of mortality, with ischaemic heart disease contributing significantly to the burden. Primary and secondary prevention strategies are essential to reducing the incidence and recurrence of acute myocardial infarction. Healthcare professionals are no longer the sole source of health education; the Internet, including tools powered by artificial intelligence, is also widely utilized. This study evaluates the accuracy and the readability of large language model (LLM)-generated information on cardiovascular primary and secondary prevention.</p><p><strong>Methods and results: </strong>An observational study assessed LLM's responses to two tailored questions about acute myocardial infarction risk prevention. The LLM used was ChatGPT (4o version). Expert cardiologists evaluated the accuracy of each response using a Likert scale, while readability was assessed with the Flesch Reading Ease Score (FRES). ChatGPT-4o provided comprehensive and accurate responses for 15 out of 20 (75%) of the items. Readability scores were low, with median FRES indicating that both primary and secondary prevention content were difficult to understand. Specialized clinical topics exhibited lower accuracy and readability compared to the other topics.</p><p><strong>Conclusion: </strong>The current study demonstrated that ChatGPT-4o provided accurate information on primary and secondary prevention, although its readability was assessed as difficult. However, clinical oversight still remains critical to bridge gaps in accuracy and readability and ensure optimal patient outcomes.</p>","PeriodicalId":72965,"journal":{"name":"European heart journal. Digital health","volume":"6 5","pages":"1069-1075"},"PeriodicalIF":4.4000,"publicationDate":"2025-08-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12450516/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"European heart journal. Digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/ehjdh/ztaf085","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/9/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"CARDIAC & CARDIOVASCULAR SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
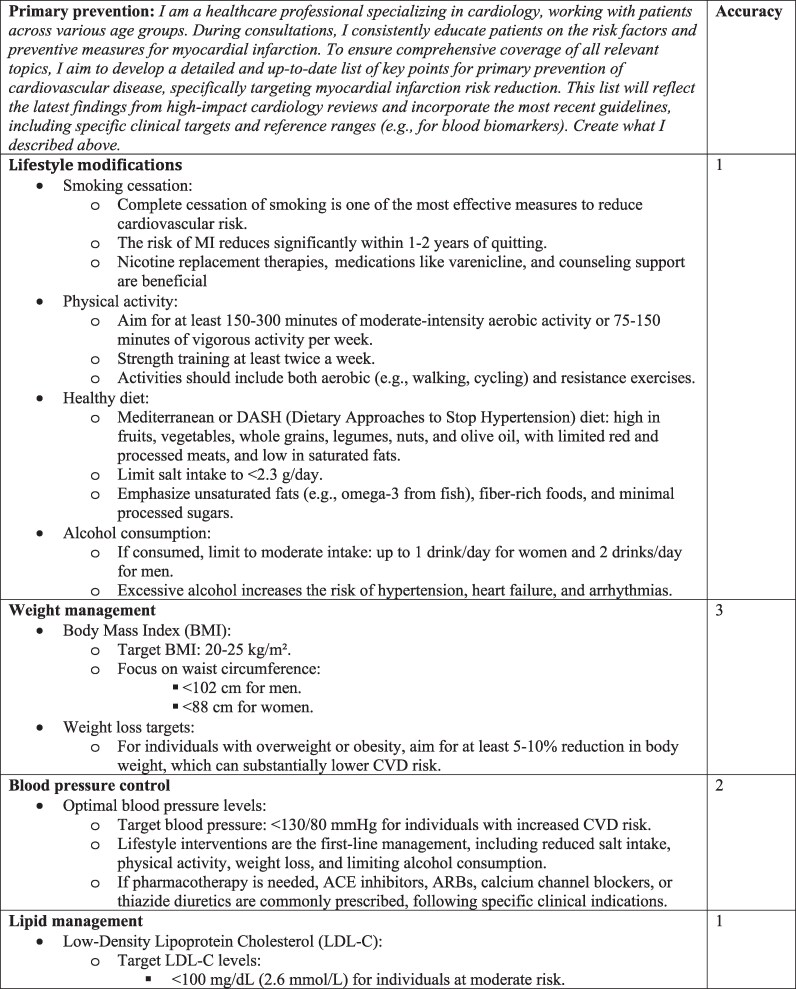
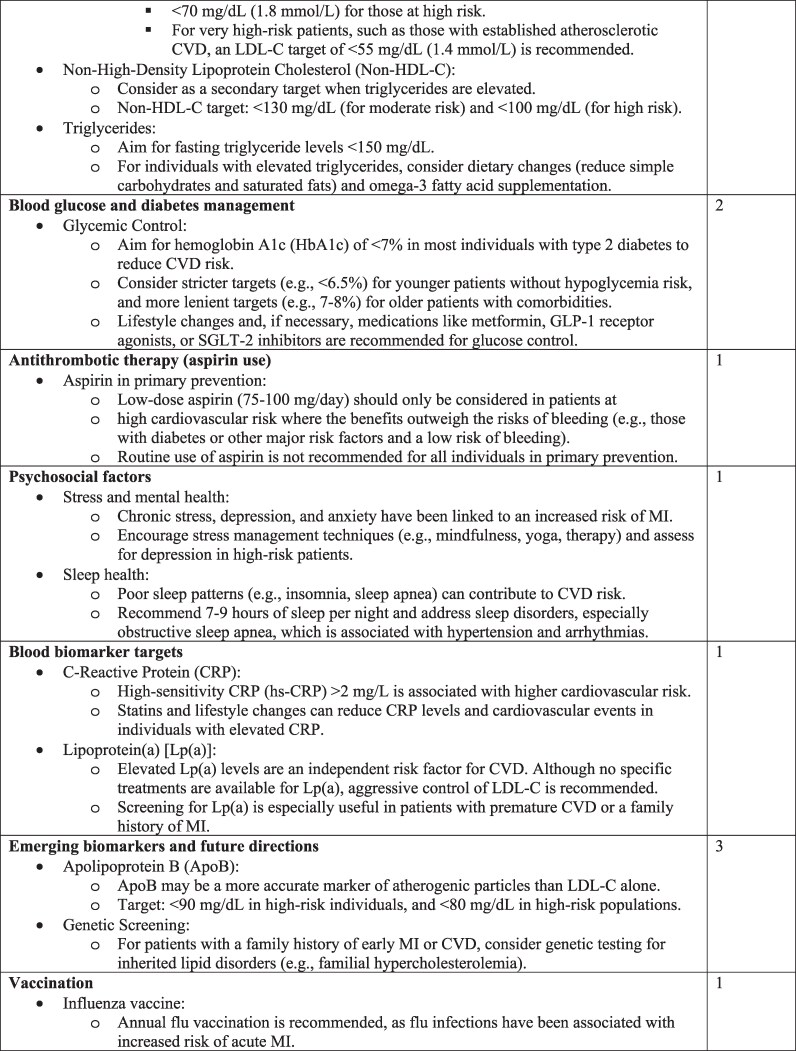
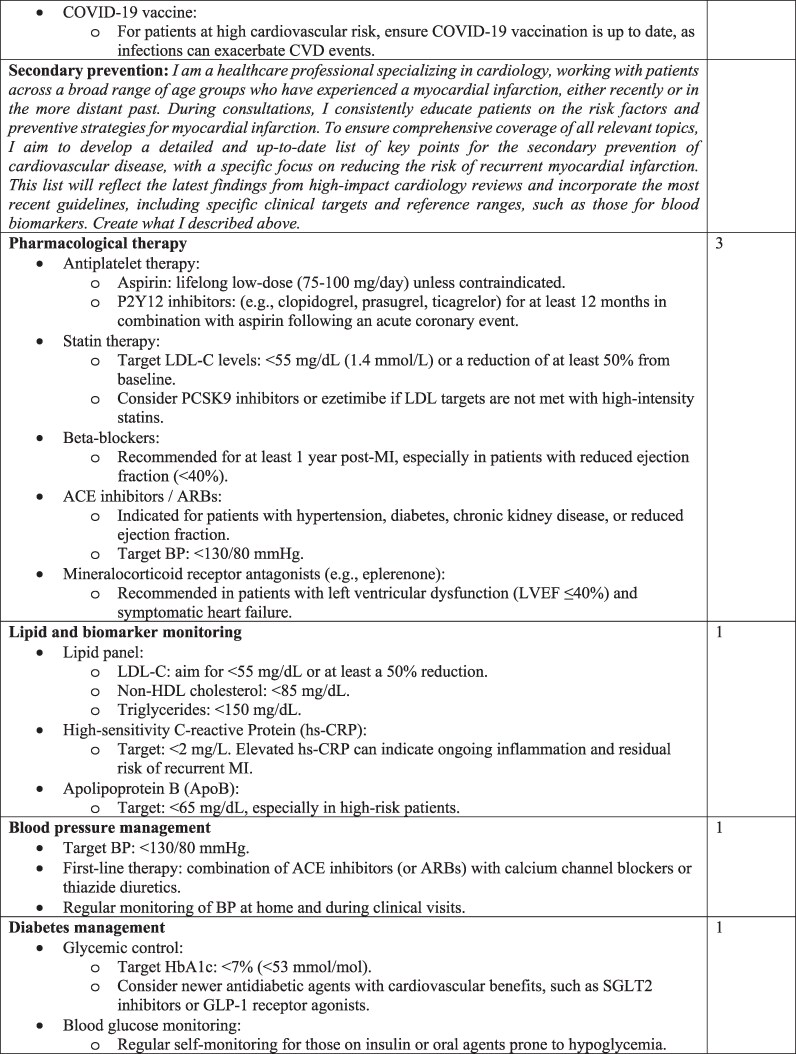
Aims: Cardiovascular diseases are the leading global cause of mortality, with ischaemic heart disease contributing significantly to the burden. Primary and secondary prevention strategies are essential to reducing the incidence and recurrence of acute myocardial infarction. Healthcare professionals are no longer the sole source of health education; the Internet, including tools powered by artificial intelligence, is also widely utilized. This study evaluates the accuracy and the readability of large language model (LLM)-generated information on cardiovascular primary and secondary prevention.
Methods and results: An observational study assessed LLM's responses to two tailored questions about acute myocardial infarction risk prevention. The LLM used was ChatGPT (4o version). Expert cardiologists evaluated the accuracy of each response using a Likert scale, while readability was assessed with the Flesch Reading Ease Score (FRES). ChatGPT-4o provided comprehensive and accurate responses for 15 out of 20 (75%) of the items. Readability scores were low, with median FRES indicating that both primary and secondary prevention content were difficult to understand. Specialized clinical topics exhibited lower accuracy and readability compared to the other topics.
Conclusion: The current study demonstrated that ChatGPT-4o provided accurate information on primary and secondary prevention, although its readability was assessed as difficult. However, clinical oversight still remains critical to bridge gaps in accuracy and readability and ensure optimal patient outcomes.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


