From open-vocabulary to vocabulary-free semantic segmentation
IF 3.3
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
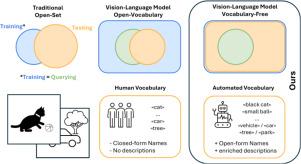
Open-vocabulary semantic segmentation enables models to identify novel object categories beyond their training data. While this flexibility represents a significant advancement, current approaches still rely on manually specified class names as input, creating an inherent bottleneck in real-world applications. This work proposes a Vocabulary-Free Semantic Segmentation pipeline, eliminating the need for predefined class vocabularies. Specifically, we address the chicken-and-egg problem where users need knowledge of all potential objects within a scene to identify them, yet the purpose of segmentation is often to discover these objects. The proposed approach leverages Vision–Language Models to automatically recognize objects and generate appropriate class names, aiming to solve the challenge of class specification and naming quality. Through extensive experiments on several public datasets, we highlight the crucial role of the text encoder in model performance, particularly when the image text classes are paired with generated descriptions. Despite the challenges introduced by the sensitivity of the segmentation text encoder to false negatives within the class tagging process, which adds complexity to the task, we demonstrate that our fully automated pipeline significantly enhances vocabulary-free segmentation accuracy across diverse real-world scenarios. Code is available at https://github.com/klarareichard/open-vocab2free-seg.
从开放词汇到无词汇的语义切分
开放词汇语义分割使模型能够识别训练数据之外的新对象类别。虽然这种灵活性代表了一个重大的进步,但当前的方法仍然依赖于手动指定的类名作为输入,这在实际应用程序中造成了固有的瓶颈。这项工作提出了一个不需要词汇表的语义分割管道,消除了对预定义类词汇表的需要。具体来说,我们解决了先有鸡还是先有蛋的问题,用户需要了解场景中所有潜在对象的知识来识别它们,而分割的目的通常是发现这些对象。该方法利用视觉语言模型自动识别对象并生成合适的类名,旨在解决类规范和命名质量的难题。通过对几个公共数据集的大量实验,我们强调了文本编码器在模型性能中的关键作用,特别是当图像文本类与生成的描述配对时。尽管在类标记过程中,切分文本编码器对假阴性的敏感性带来了挑战,这增加了任务的复杂性,但我们证明了我们的全自动管道在不同的现实世界场景中显著提高了无词汇表切分的准确性。代码可从https://github.com/klarareichard/open-vocab2free-seg获得。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Pattern Recognition Letters
工程技术-计算机:人工智能
CiteScore
12.40
自引率
5.90%
发文量
287
审稿时长
9.1 months
期刊介绍:
Pattern Recognition Letters aims at rapid publication of concise articles of a broad interest in pattern recognition.
Subject areas include all the current fields of interest represented by the Technical Committees of the International Association of Pattern Recognition, and other developing themes involving learning and recognition.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


