Anila Jaleel, Umair Aziz, Ghulam Farid, Muhammad Zahid Bashir, Tehmasp Rehman Mirza, Syed Mohammad Khizar Abbas, Shiraz Aslam, Rana Muhammad Hassaan Sikander
{"title":"Evaluating the Potential and Accuracy of ChatGPT-3.5 and 4.0 in Medical Licensing and In-Training Examinations: Systematic Review and Meta-Analysis.","authors":"Anila Jaleel, Umair Aziz, Ghulam Farid, Muhammad Zahid Bashir, Tehmasp Rehman Mirza, Syed Mohammad Khizar Abbas, Shiraz Aslam, Rana Muhammad Hassaan Sikander","doi":"10.2196/68070","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Artificial intelligence (AI) has significantly impacted health care, medicine, and radiology, offering personalized treatment plans, simplified workflows, and informed clinical decisions. ChatGPT (OpenAI), a conversational AI model, has revolutionized health care and medical education by simulating clinical scenarios and improving communication skills. However, inconsistent performance across medical licensing examinations and variability between countries and specialties highlight the need for further research on contextual factors influencing AI accuracy and exploring its potential to enhance technical proficiency and soft skills, making AI a reliable tool in patient care and medical education.</p><p><strong>Objective: </strong>This systematic review aims to evaluate and compare the accuracy and potential of ChatGPT-3.5 and 4.0 in medical licensing and in-training residency examinations across various countries and specialties.</p><p><strong>Methods: </strong>A systematic review and meta-analysis were conducted, adhering to the PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) guidelines. Data were collected from multiple reputable databases (Scopus, PubMed, JMIR Publications, Elsevier, BMJ, and Wiley Online Library), focusing on studies published from January 2023 to July 2024. Analysis specifically targeted research assessing ChatGPT's efficacy in medical licensing exams, excluding studies not related to this focus or published in languages other than English. Ultimately, 53 studies were included, providing a robust dataset for comparing the accuracy rates of ChatGPT-3.5 and 4.0.</p><p><strong>Results: </strong>ChatGPT-4 outperformed ChatGPT-3.5 in medical licensing exams, achieving a pooled accuracy of 81.8%, compared to ChatGPT-3.5's 60.8%. In in-training residency exams, ChatGPT-4 achieved an accuracy rate of 72.2%, compared to 57.7% for ChatGPT-3.5. The forest plot presented a risk ratio of 1.36 (95% CI 1.30-1.43), demonstrating that ChatGPT-4 was 36% more likely to provide correct answers than ChatGPT-3.5 across both medical licensing and residency exams. These results indicate that ChatGPT-4 significantly outperforms ChatGPT-3.5, but the performance advantage varies depending on the exam type. This highlights the importance of targeted improvements and further research to optimize ChatGPT-4's performance in specific educational and clinical settings.</p><p><strong>Conclusions: </strong>ChatGPT-4.0 and 3.5 show promising results in enhancing medical education and supporting clinical decision-making, but they cannot replace the comprehensive skill set required for effective medical practice. Future research should focus on improving AI's capabilities in interpreting complex clinical data and enhancing its reliability as an educational resource.</p>","PeriodicalId":36236,"journal":{"name":"JMIR Medical Education","volume":"11 ","pages":"e68070"},"PeriodicalIF":3.2000,"publicationDate":"2025-09-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12495368/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Education","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/68070","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"EDUCATION, SCIENTIFIC DISCIPLINES","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Artificial intelligence (AI) has significantly impacted health care, medicine, and radiology, offering personalized treatment plans, simplified workflows, and informed clinical decisions. ChatGPT (OpenAI), a conversational AI model, has revolutionized health care and medical education by simulating clinical scenarios and improving communication skills. However, inconsistent performance across medical licensing examinations and variability between countries and specialties highlight the need for further research on contextual factors influencing AI accuracy and exploring its potential to enhance technical proficiency and soft skills, making AI a reliable tool in patient care and medical education.
Objective: This systematic review aims to evaluate and compare the accuracy and potential of ChatGPT-3.5 and 4.0 in medical licensing and in-training residency examinations across various countries and specialties.
Methods: A systematic review and meta-analysis were conducted, adhering to the PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) guidelines. Data were collected from multiple reputable databases (Scopus, PubMed, JMIR Publications, Elsevier, BMJ, and Wiley Online Library), focusing on studies published from January 2023 to July 2024. Analysis specifically targeted research assessing ChatGPT's efficacy in medical licensing exams, excluding studies not related to this focus or published in languages other than English. Ultimately, 53 studies were included, providing a robust dataset for comparing the accuracy rates of ChatGPT-3.5 and 4.0.
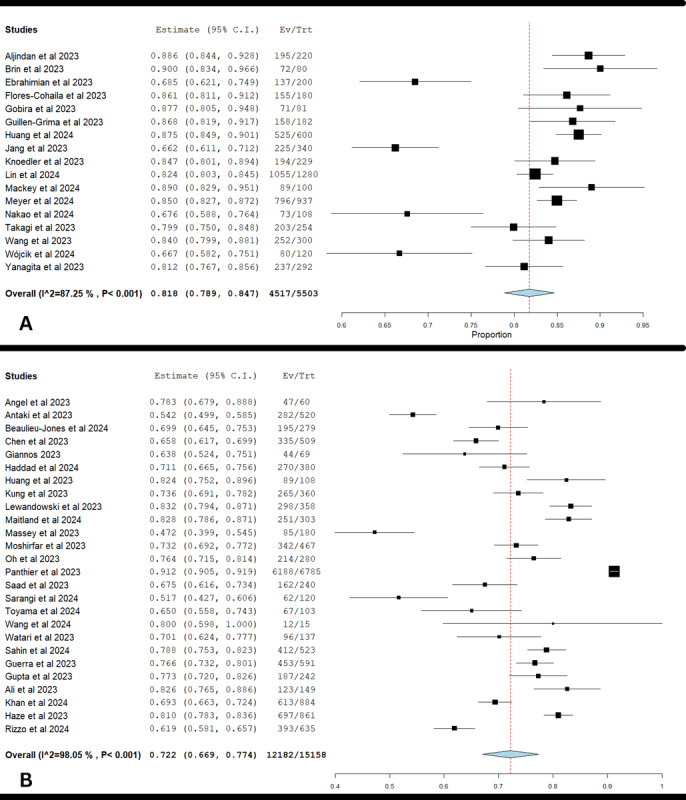
Results: ChatGPT-4 outperformed ChatGPT-3.5 in medical licensing exams, achieving a pooled accuracy of 81.8%, compared to ChatGPT-3.5's 60.8%. In in-training residency exams, ChatGPT-4 achieved an accuracy rate of 72.2%, compared to 57.7% for ChatGPT-3.5. The forest plot presented a risk ratio of 1.36 (95% CI 1.30-1.43), demonstrating that ChatGPT-4 was 36% more likely to provide correct answers than ChatGPT-3.5 across both medical licensing and residency exams. These results indicate that ChatGPT-4 significantly outperforms ChatGPT-3.5, but the performance advantage varies depending on the exam type. This highlights the importance of targeted improvements and further research to optimize ChatGPT-4's performance in specific educational and clinical settings.
Conclusions: ChatGPT-4.0 and 3.5 show promising results in enhancing medical education and supporting clinical decision-making, but they cannot replace the comprehensive skill set required for effective medical practice. Future research should focus on improving AI's capabilities in interpreting complex clinical data and enhancing its reliability as an educational resource.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


