{"title":"Evaluating large language models in pediatric fever management: a two-layer study.","authors":"Guijun Yang, Hejun Jiang, Shuhua Yuan, Mingyu Tang, Jing Zhang, Jilei Lin, Jiande Chen, Jiajun Yuan, Liebin Zhao, Yong Yin","doi":"10.3389/fdgth.2025.1610671","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Pediatric fever is a prevalent concern, often causing parental anxiety and frequent medical consultations. While large language models (LLMs) such as ChatGPT, Perplexity, and YouChat show promise in enhancing medical communication and education, their efficacy in addressing complex pediatric fever-related questions remains underexplored, particularly from the perspectives of medical professionals and patients' relatives.</p><p><strong>Objective: </strong>This study aimed to explore the differences and similarities among four common large language models (ChatGPT3.5, ChatGPT4.0, YouChat, and Perplexity) in answering thirty pediatric fever-related questions and to examine how doctors and pediatric patients' relatives evaluate the LLM-generated answers based on predefined criteria.</p><p><strong>Methods: </strong>The study selected thirty fever-related pediatric questions answered by the four models. Twenty doctors rated these responses across four dimensions. To conduct the survey among pediatric patients' relatives, we eliminated certain responses that we deemed to pose safety risks or be misleading. Based on the doctors' questionnaire, the thirty questions were divided into six groups, each evaluated by twenty pediatric relatives. The Tukey <i>post-hoc</i> test was used to check for significant differences. Some of pediatric relatives was revisited for deeper insights into the results.</p><p><strong>Results: </strong>In the doctors' questionnaire, ChatGPT3.5 and ChatGPT4.0 outperformed YouChat and Perplexity in all dimensions, with no significant difference between ChatGPT3.5 and ChatGPT4.0 or between YouChat and Perplexity. All models scored significantly better in accuracy than other dimensions. In the pediatric relatives' questionnaire, no significant differences were found among the models, with revisits revealing some reasons for these results.</p><p><strong>Conclusions: </strong>Internet searches (YouChat and Perplexity) did not improve the ability of large language models to answer medical questions as expected. Patients lacked the ability to understand and analyze model responses due to a lack of professional knowledge and a lack of central points in model answers. When developing large language models for patient use, it's important to highlight the central points of the answers and ensure they are easily understandable.</p>","PeriodicalId":73078,"journal":{"name":"Frontiers in digital health","volume":"7 ","pages":"1610671"},"PeriodicalIF":3.2000,"publicationDate":"2025-09-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12441047/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fdgth.2025.1610671","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Pediatric fever is a prevalent concern, often causing parental anxiety and frequent medical consultations. While large language models (LLMs) such as ChatGPT, Perplexity, and YouChat show promise in enhancing medical communication and education, their efficacy in addressing complex pediatric fever-related questions remains underexplored, particularly from the perspectives of medical professionals and patients' relatives.
Objective: This study aimed to explore the differences and similarities among four common large language models (ChatGPT3.5, ChatGPT4.0, YouChat, and Perplexity) in answering thirty pediatric fever-related questions and to examine how doctors and pediatric patients' relatives evaluate the LLM-generated answers based on predefined criteria.
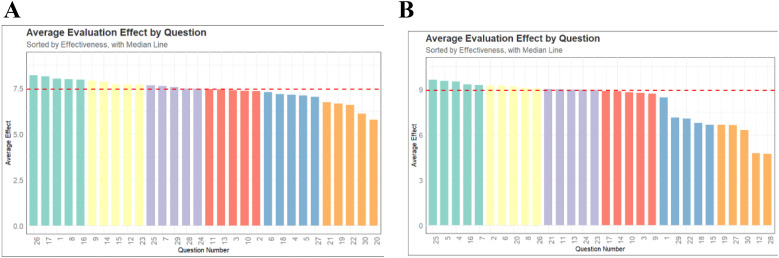
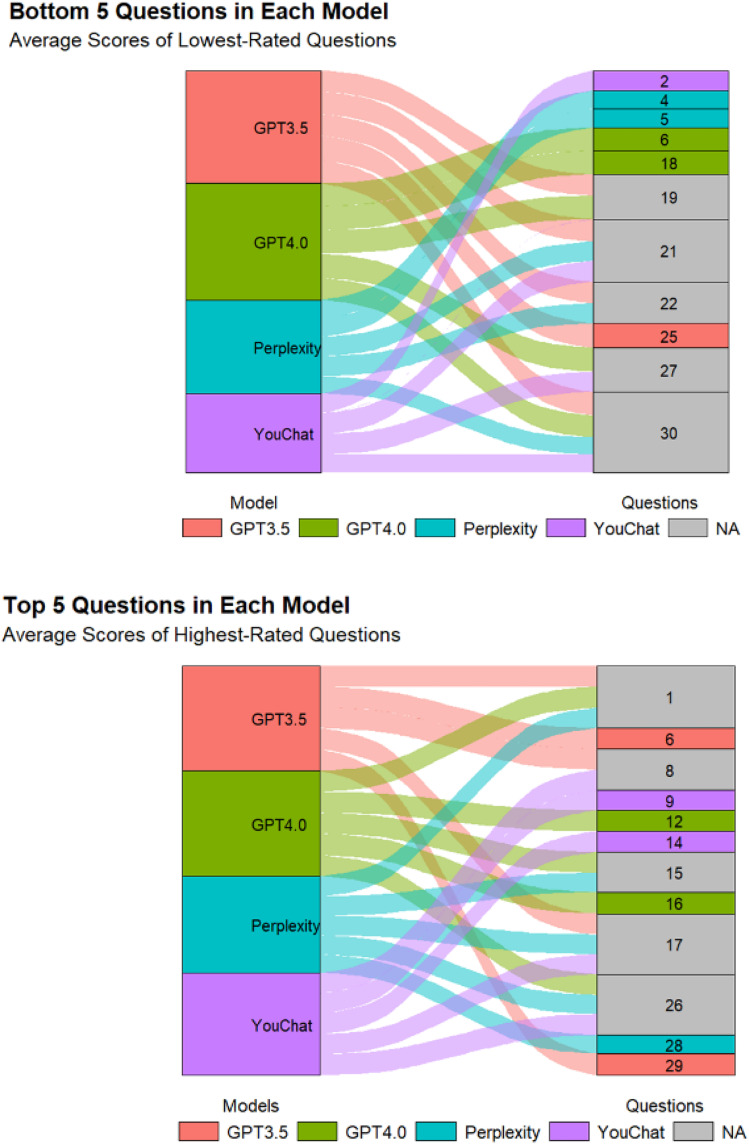
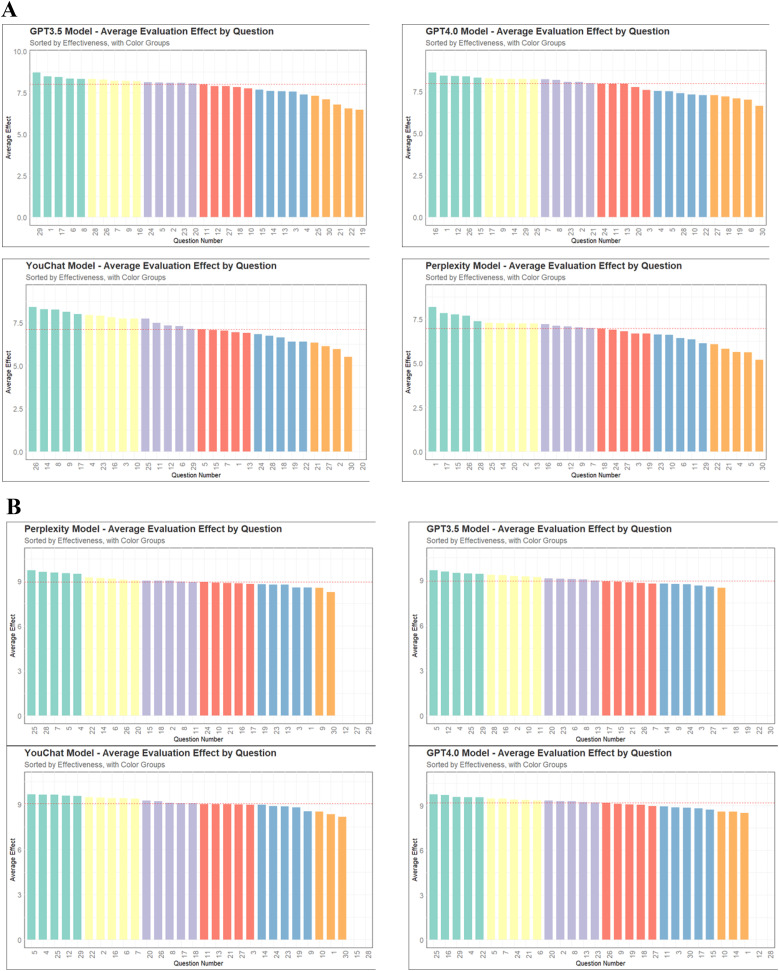
Methods: The study selected thirty fever-related pediatric questions answered by the four models. Twenty doctors rated these responses across four dimensions. To conduct the survey among pediatric patients' relatives, we eliminated certain responses that we deemed to pose safety risks or be misleading. Based on the doctors' questionnaire, the thirty questions were divided into six groups, each evaluated by twenty pediatric relatives. The Tukey post-hoc test was used to check for significant differences. Some of pediatric relatives was revisited for deeper insights into the results.
Results: In the doctors' questionnaire, ChatGPT3.5 and ChatGPT4.0 outperformed YouChat and Perplexity in all dimensions, with no significant difference between ChatGPT3.5 and ChatGPT4.0 or between YouChat and Perplexity. All models scored significantly better in accuracy than other dimensions. In the pediatric relatives' questionnaire, no significant differences were found among the models, with revisits revealing some reasons for these results.
Conclusions: Internet searches (YouChat and Perplexity) did not improve the ability of large language models to answer medical questions as expected. Patients lacked the ability to understand and analyze model responses due to a lack of professional knowledge and a lack of central points in model answers. When developing large language models for patient use, it's important to highlight the central points of the answers and ensure they are easily understandable.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


