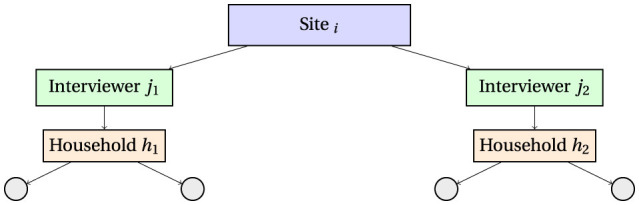
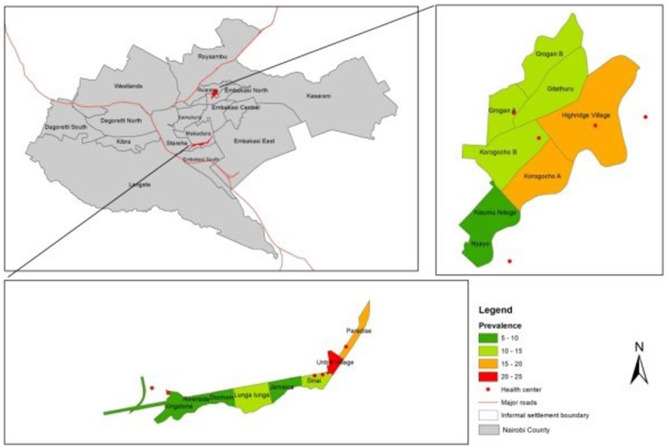
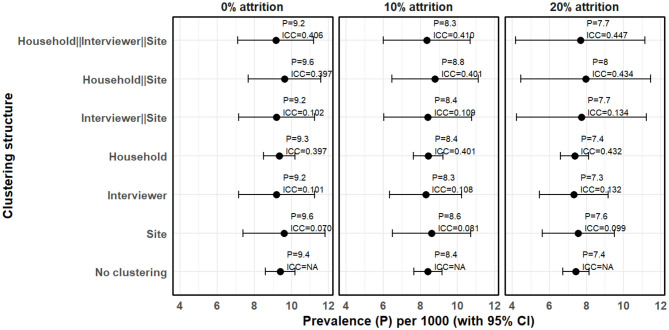
Accounting for clustering for self-reported outcomes in the design and analysis of population-based surveys: A case study of estimation of prevalence of epilepsy in Nairobi, Kenya.
Daniel M Mwanga, Isaac C Kipchirchir, George O Muhua, Charles R Newton, Damazo T Kadengye
{"title":"Accounting for clustering for self-reported outcomes in the design and analysis of population-based surveys: A case study of estimation of prevalence of epilepsy in Nairobi, Kenya.","authors":"Daniel M Mwanga, Isaac C Kipchirchir, George O Muhua, Charles R Newton, Damazo T Kadengye","doi":"10.3389/frma.2025.1583476","DOIUrl":null,"url":null,"abstract":"<p><p>Population-based surveys are common for estimation of important public health metrics such as prevalence. Often, survey data tend to have a hierarchical structure where households are clustered within villages or sites and interviewers are assigned specific locations to conduct the survey. Self-reported outcomes such as diagnosis of diseases like epilepsy present more complex structure, where interviewer or physician-related effects may bias the results. Standard estimation techniques that ignore clustering may lead to underestimated standard errors and overconfident inferences. In this paper, we examine these effects for estimation of prevalence of epilepsy in a two-stage population-based survey in Nairobi and we discuss how clustering can be taken into account in design and analysis of population-based prevalence studies. We used data from the Epilepsy Pathway Innovation in Africa project conducted in Nairobi and simulated attrition levels at 10% and 20% assuming missing at random (MAR) mechanism. Attrition was accounted for using sequential k-nearest neighbor method. We adjusted the expected prevalence based on clustering at multiple levels, such as site, interviewer and household using a random effects model. Intraclass correlation (ICC) > 0.1 indicated presence of substantial clustering. We report point estimates with 95% confidence interval (CI). Crude prevalence of epilepsy was 9.40 cases per 1,000 people (95% CI: 8.60-10.20). There was substantial clustering at household level (ICC = 0.397), interviewer level (ICC = 0.101) and site level (ICC = 0.070). Prevalence adjusted for clustering at household, interviewer and site was 9.15/1,000 (95% CI 7.11-11.20). Overall, not accounting for clustering was associated with underestimation of standard errors. Not accounting for attrition on the other hand led to underestimation of prevalence. Imputation of the missing data due to attrition mitigated the attrition bias under appropriate assumptions. Accounting for clustering, particularly household, interviewer and site levels, is critical for valid estimation of standard errors in population-based surveys. Rigorous training and pre-survey testing can minimize measurement error in self-reported outcomes. Attrition can lead to underestimation of prevalence if not properly addressed. Attrition bias can be minimized by conducting targeted mobilization of participants to improve response rates and using statistical methods such as multiple imputation or machine learning-based imputation methods to address it.</p>","PeriodicalId":73104,"journal":{"name":"Frontiers in research metrics and analytics","volume":"10 ","pages":"1583476"},"PeriodicalIF":1.6000,"publicationDate":"2025-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12433999/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in research metrics and analytics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/frma.2025.1583476","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Population-based surveys are common for estimation of important public health metrics such as prevalence. Often, survey data tend to have a hierarchical structure where households are clustered within villages or sites and interviewers are assigned specific locations to conduct the survey. Self-reported outcomes such as diagnosis of diseases like epilepsy present more complex structure, where interviewer or physician-related effects may bias the results. Standard estimation techniques that ignore clustering may lead to underestimated standard errors and overconfident inferences. In this paper, we examine these effects for estimation of prevalence of epilepsy in a two-stage population-based survey in Nairobi and we discuss how clustering can be taken into account in design and analysis of population-based prevalence studies. We used data from the Epilepsy Pathway Innovation in Africa project conducted in Nairobi and simulated attrition levels at 10% and 20% assuming missing at random (MAR) mechanism. Attrition was accounted for using sequential k-nearest neighbor method. We adjusted the expected prevalence based on clustering at multiple levels, such as site, interviewer and household using a random effects model. Intraclass correlation (ICC) > 0.1 indicated presence of substantial clustering. We report point estimates with 95% confidence interval (CI). Crude prevalence of epilepsy was 9.40 cases per 1,000 people (95% CI: 8.60-10.20). There was substantial clustering at household level (ICC = 0.397), interviewer level (ICC = 0.101) and site level (ICC = 0.070). Prevalence adjusted for clustering at household, interviewer and site was 9.15/1,000 (95% CI 7.11-11.20). Overall, not accounting for clustering was associated with underestimation of standard errors. Not accounting for attrition on the other hand led to underestimation of prevalence. Imputation of the missing data due to attrition mitigated the attrition bias under appropriate assumptions. Accounting for clustering, particularly household, interviewer and site levels, is critical for valid estimation of standard errors in population-based surveys. Rigorous training and pre-survey testing can minimize measurement error in self-reported outcomes. Attrition can lead to underestimation of prevalence if not properly addressed. Attrition bias can be minimized by conducting targeted mobilization of participants to improve response rates and using statistical methods such as multiple imputation or machine learning-based imputation methods to address it.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


