{"title":"Leveraging large language and vision models for knowledge extraction from large-scale image–text colonoscopy records","authors":"Shuo Wang, Yan Zhu, Zhiwei Yang, Xiaoyuan Luo, Yizhe Zhang, Peiyao Fu, Haoran Wang, Manning Wang, Zhijian Song, Quanlin Li, Pinghong Zhou, Yike Guo","doi":"10.1038/s41551-025-01500-x","DOIUrl":null,"url":null,"abstract":"<p>The development of artificial intelligence systems for colonoscopy analysis often necessitates expert-annotated image datasets. However, limitations in dataset size and diversity impede model performance and generalization. Image–text colonoscopy records from routine clinical practice, comprising millions of images and text reports, serve as a valuable data source, although annotating them is labour intensive. Here we leverage recent advancements in large language and vision models and propose EndoKED, a data mining paradigm for deep knowledge extraction and distillation. EndoKED automates the transformation of raw colonoscopy records into image datasets with pixel-level annotation. We apply EndoKED to multicentre datasets of raw colonoscopy records (~1 million images), showing its superior performance in detecting polyps at the report and image levels, as well as annotating polyps at the pixel level. The state-of-the-art performance and generalization ability of polyp segmentation models are achieved through EndoKED pretraining. Furthermore, the EndoKED vision backbone enables data-efficient learning for optical biopsy, achieving expert-level performance in internal, external and prospective validation datasets.</p>","PeriodicalId":19063,"journal":{"name":"Nature Biomedical Engineering","volume":"35 1","pages":""},"PeriodicalIF":26.8000,"publicationDate":"2025-09-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Biomedical Engineering","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1038/s41551-025-01500-x","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"ENGINEERING, BIOMEDICAL","Score":null,"Total":0}
引用次数: 0
Abstract
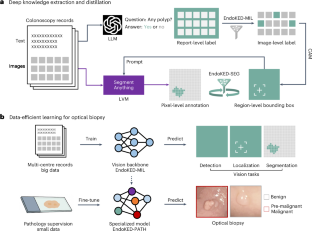
The development of artificial intelligence systems for colonoscopy analysis often necessitates expert-annotated image datasets. However, limitations in dataset size and diversity impede model performance and generalization. Image–text colonoscopy records from routine clinical practice, comprising millions of images and text reports, serve as a valuable data source, although annotating them is labour intensive. Here we leverage recent advancements in large language and vision models and propose EndoKED, a data mining paradigm for deep knowledge extraction and distillation. EndoKED automates the transformation of raw colonoscopy records into image datasets with pixel-level annotation. We apply EndoKED to multicentre datasets of raw colonoscopy records (~1 million images), showing its superior performance in detecting polyps at the report and image levels, as well as annotating polyps at the pixel level. The state-of-the-art performance and generalization ability of polyp segmentation models are achieved through EndoKED pretraining. Furthermore, the EndoKED vision backbone enables data-efficient learning for optical biopsy, achieving expert-level performance in internal, external and prospective validation datasets.
期刊介绍:
Nature Biomedical Engineering is an online-only monthly journal that was launched in January 2017. It aims to publish original research, reviews, and commentary focusing on applied biomedicine and health technology. The journal targets a diverse audience, including life scientists who are involved in developing experimental or computational systems and methods to enhance our understanding of human physiology. It also covers biomedical researchers and engineers who are engaged in designing or optimizing therapies, assays, devices, or procedures for diagnosing or treating diseases. Additionally, clinicians, who make use of research outputs to evaluate patient health or administer therapy in various clinical settings and healthcare contexts, are also part of the target audience.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


