An open invisible space enabled by reconfigurable metasurfaces and self-play reinforcement learning
IF 23.4
Q1 OPTICS
引用次数: 0
Abstract
An open, dynamic, and electromagnetically invisible space has been constructed using reconfigurable metasurfaces and self-play reinforcement learning. A model named MetaSeeker is proposed to optimize the cloaking performance of randomly distributed metasurfaces. The hidden objects can move freely within the constructed invisible space, with environmental similarity of 99.5%. This advancement provides an innovative solution for cloaking technologies in complex environments.
An open invisible space enabled by reconfigurable metasurfaces and self-play reinforcement learning.
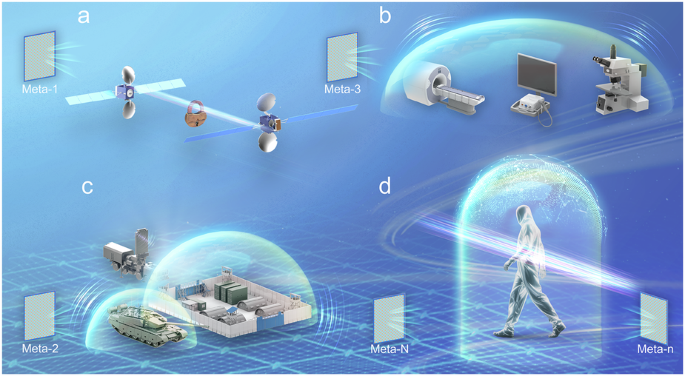
一个开放的无形空间,由可重构的元表面和自我强化学习实现
利用可重构元表面和自玩强化学习,构建了一个开放的、动态的、电磁不可见的空间。为了优化随机分布的元表面的隐身性能,提出了MetaSeeker模型。隐藏物体可以在构建的隐形空间内自由移动,环境相似度达到99.5%。这一进步为复杂环境中的隐形技术提供了一种创新的解决方案。一个开放的无形空间,由可重构的元表面和自我强化学习实现。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Light-Science & Applications
数理科学, 物理学I, 光学, 凝聚态物性 II :电子结构、电学、磁学和光学性质, 无机非金属材料, 无机非金属类光电信息与功能材料, 工程与材料, 信息科学, 光学和光电子学, 光学和光电子材料, 非线性光学与量子光学
自引率
0.00%
发文量
803
审稿时长
2.1 months
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


