Quang Nguyen, Duy-Anh Nguyen, Khang Dang, Siyin Liu, Sophia Y Wang, William A Woof, Peter B M Thomas, Praveen J Patel, Konstantinos Balaskas, Johan H Thygesen, Honghan Wu, Nikolas Pontikos
{"title":"Advancing Question-Answering in Ophthalmology With Retrieval-Augmented Generation: Benchmarking Open-Source and Proprietary Large Language Models.","authors":"Quang Nguyen, Duy-Anh Nguyen, Khang Dang, Siyin Liu, Sophia Y Wang, William A Woof, Peter B M Thomas, Praveen J Patel, Konstantinos Balaskas, Johan H Thygesen, Honghan Wu, Nikolas Pontikos","doi":"10.1167/tvst.14.9.18","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>The purpose of this study was to evaluate the application of combining information retrieval with text generation using Retrieval-Augmented Generation (RAG) to benchmark the performance of open-source and proprietary generative large language models (LLMs) in question-answering in ophthalmology.</p><p><strong>Methods: </strong>Our dataset comprised 260 multiple-choice questions sourced from two question-answer banks designed to assess ophthalmic knowledge: the American Academy of Ophthalmology's (AAO) Basic and Clinical Science Course (BCSC) Self-Assessment program and OphthoQuestions. Our RAG pipeline retrieves documents in the BCSC companion textbook using ChromaDB, followed by reranking with Cohere to refine the context provided to the LLMs. Generative Pretrained Transformer (GPT)-4-turbo and 3 open-source models (Llama-3-70B, Gemma-2-27B, and Mixtral-8 × 7B) are benchmarked using zero-shot, zero-shot with Chain-of-Thought (zero-shot-CoT), and RAG. Model performance is evaluated using accuracy on the two datasets. Quantization is applied to improve the efficiency of the open-source models. Effects of quantization level are also measured.</p><p><strong>Results: </strong>Using RAG, GPT-4-turbo's accuracy increased by 11.54% on BCSC and by 10.96% on OphthoQuestions. Importantly, the RAG pipeline greatly enhances overall performance of Llama-3 by 23.85%, Gemma-2 by 17.11%, and Mixtral-8 × 7B by 22.11%. Zero-shot-CoT had overall no significant improvement on the models' performance. Quantization using 4 bit was shown to be as effective as using 8 bits while requiring half the resources.</p><p><strong>Conclusions: </strong>Our work demonstrates that integrating RAG significantly enhances LLM accuracy especially for smaller LLMs.</p><p><strong>Translation relevance: </strong>Using our RAG, smaller privacy-preserving open-source LLMs can be run in sensitive and resource-constrained environments, such as within hospitals, offering a viable alternative to cloud-based LLMs like GPT-4-turbo.</p>","PeriodicalId":23322,"journal":{"name":"Translational Vision Science & Technology","volume":"14 9","pages":"18"},"PeriodicalIF":2.6000,"publicationDate":"2025-09-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12439504/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Translational Vision Science & Technology","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1167/tvst.14.9.18","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"OPHTHALMOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Purpose: The purpose of this study was to evaluate the application of combining information retrieval with text generation using Retrieval-Augmented Generation (RAG) to benchmark the performance of open-source and proprietary generative large language models (LLMs) in question-answering in ophthalmology.
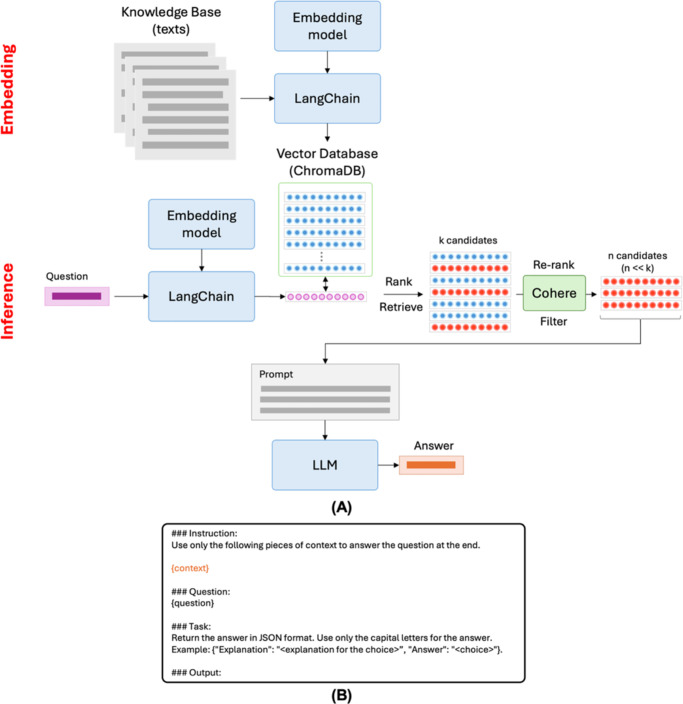
Methods: Our dataset comprised 260 multiple-choice questions sourced from two question-answer banks designed to assess ophthalmic knowledge: the American Academy of Ophthalmology's (AAO) Basic and Clinical Science Course (BCSC) Self-Assessment program and OphthoQuestions. Our RAG pipeline retrieves documents in the BCSC companion textbook using ChromaDB, followed by reranking with Cohere to refine the context provided to the LLMs. Generative Pretrained Transformer (GPT)-4-turbo and 3 open-source models (Llama-3-70B, Gemma-2-27B, and Mixtral-8 × 7B) are benchmarked using zero-shot, zero-shot with Chain-of-Thought (zero-shot-CoT), and RAG. Model performance is evaluated using accuracy on the two datasets. Quantization is applied to improve the efficiency of the open-source models. Effects of quantization level are also measured.
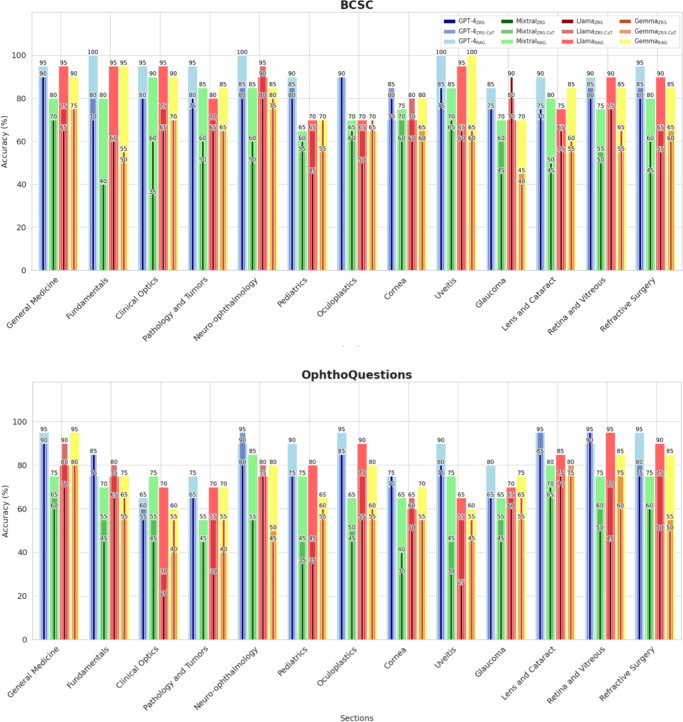
Results: Using RAG, GPT-4-turbo's accuracy increased by 11.54% on BCSC and by 10.96% on OphthoQuestions. Importantly, the RAG pipeline greatly enhances overall performance of Llama-3 by 23.85%, Gemma-2 by 17.11%, and Mixtral-8 × 7B by 22.11%. Zero-shot-CoT had overall no significant improvement on the models' performance. Quantization using 4 bit was shown to be as effective as using 8 bits while requiring half the resources.
Conclusions: Our work demonstrates that integrating RAG significantly enhances LLM accuracy especially for smaller LLMs.
Translation relevance: Using our RAG, smaller privacy-preserving open-source LLMs can be run in sensitive and resource-constrained environments, such as within hospitals, offering a viable alternative to cloud-based LLMs like GPT-4-turbo.
期刊介绍:
Translational Vision Science & Technology (TVST), an official journal of the Association for Research in Vision and Ophthalmology (ARVO), an international organization whose purpose is to advance research worldwide into understanding the visual system and preventing, treating and curing its disorders, is an online, open access, peer-reviewed journal emphasizing multidisciplinary research that bridges the gap between basic research and clinical care. A highly qualified and diverse group of Associate Editors and Editorial Board Members is led by Editor-in-Chief Marco Zarbin, MD, PhD, FARVO.
The journal covers a broad spectrum of work, including but not limited to:
Applications of stem cell technology for regenerative medicine,
Development of new animal models of human diseases,
Tissue bioengineering,
Chemical engineering to improve virus-based gene delivery,
Nanotechnology for drug delivery,
Design and synthesis of artificial extracellular matrices,
Development of a true microsurgical operating environment,
Refining data analysis algorithms to improve in vivo imaging technology,
Results of Phase 1 clinical trials,
Reverse translational ("bedside to bench") research.
TVST seeks manuscripts from scientists and clinicians with diverse backgrounds ranging from basic chemistry to ophthalmic surgery that will advance or change the way we understand and/or treat vision-threatening diseases. TVST encourages the use of color, multimedia, hyperlinks, program code and other digital enhancements.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


