Luis Felipe Ensina, Matheus Matos Machado, Joice B Machado Marques, Monica Pugliese H Dos Santos, Fábio Cerqueira Lario, Chayanne Andrade Araújo, Fabiana Andrade Nunes Oliveira, Dilvan de Abreu Moreira
{"title":"Artificial intelligence for detecting anaphylaxis in electronic medical records.","authors":"Luis Felipe Ensina, Matheus Matos Machado, Joice B Machado Marques, Monica Pugliese H Dos Santos, Fábio Cerqueira Lario, Chayanne Andrade Araújo, Fabiana Andrade Nunes Oliveira, Dilvan de Abreu Moreira","doi":"10.5415/apallergy.0000000000000179","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Despite established criteria, diagnosing anaphylaxis remains challenging but critical for preventing future reactions. Fast-paced clinical settings, compounded by underrecording in electronic medical records (EMRs), increase the risk of dangerous re-exposures. Leveraging artificial intelligence through automated systems such as large language models (LLMs) offers a solution.</p><p><strong>Objective: </strong>This study aims to assess the efficacy of artificial intelligence, specifically LLMs, in autonomously identifying anaphylaxis diagnoses from EMR text to enhance patient safety and optimize care delivery.</p><p><strong>Methods: </strong>LLMs (GPT 3.5, 4, and 4 Turbo) analyzed 969 medical texts in Brazilian Portuguese, annotated as anaphylaxis-positive (48) or negative (921) by 3 expert physicians. A primary prompt simulated a general practitioner's role in reviewing medical narratives for anaphylaxis detection, with a secondary prompt incorporating World Allergy Organization (WAO) criteria. The experiments were conducted using 3 GPT configurations. The diagnostic suggestions of the LLM were compared to the physicians' diagnoses. Precision, sensitivity (recall), specificity, and accuracy values were calculated.</p><p><strong>Results: </strong>Using the primary prompt, GPT 4 Turbo detected anaphylaxis cases with 90.6% precision, 100% sensitivity, 99.5% specificity, 99.5% accuracy, and a Cohen kappa coefficient of 0.95. The inclusion of WAO criteria slightly improved the performance of older models (GPT 3.5 + 4 configuration). However, for GPT 4 Turbo, additional information did not enhance precision.</p><p><strong>Conclusion: </strong>The results highlight the potential of artificial intelligence, particularly LLMs, to automate anaphylaxis diagnosis, support healthcare professionals, and improve patient safety and care.</p>","PeriodicalId":8488,"journal":{"name":"Asia Pacific Allergy","volume":"15 3","pages":"153-158"},"PeriodicalIF":2.1000,"publicationDate":"2025-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12419321/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Asia Pacific Allergy","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.5415/apallergy.0000000000000179","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/8 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"ALLERGY","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Despite established criteria, diagnosing anaphylaxis remains challenging but critical for preventing future reactions. Fast-paced clinical settings, compounded by underrecording in electronic medical records (EMRs), increase the risk of dangerous re-exposures. Leveraging artificial intelligence through automated systems such as large language models (LLMs) offers a solution.
Objective: This study aims to assess the efficacy of artificial intelligence, specifically LLMs, in autonomously identifying anaphylaxis diagnoses from EMR text to enhance patient safety and optimize care delivery.
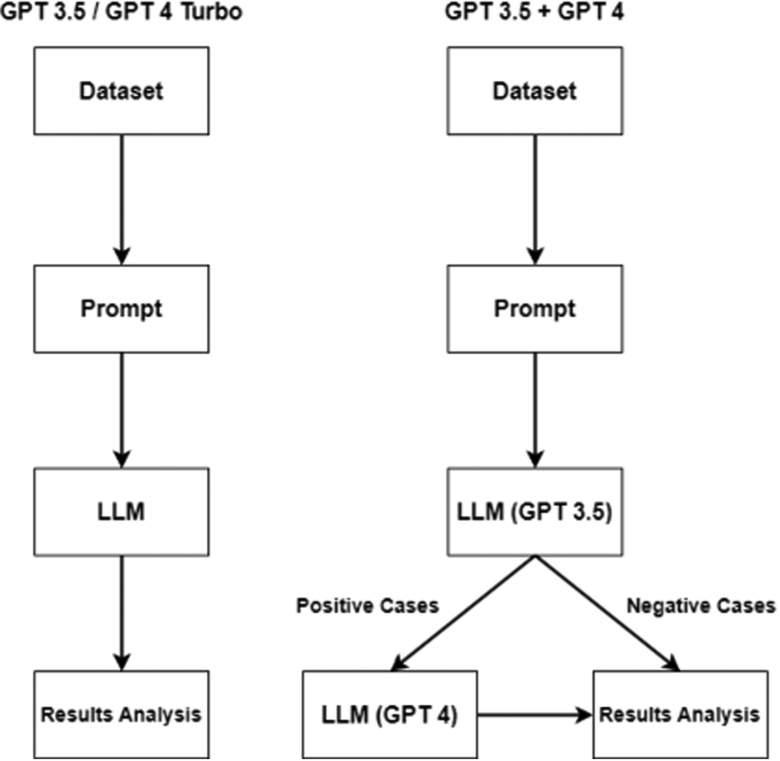
Methods: LLMs (GPT 3.5, 4, and 4 Turbo) analyzed 969 medical texts in Brazilian Portuguese, annotated as anaphylaxis-positive (48) or negative (921) by 3 expert physicians. A primary prompt simulated a general practitioner's role in reviewing medical narratives for anaphylaxis detection, with a secondary prompt incorporating World Allergy Organization (WAO) criteria. The experiments were conducted using 3 GPT configurations. The diagnostic suggestions of the LLM were compared to the physicians' diagnoses. Precision, sensitivity (recall), specificity, and accuracy values were calculated.
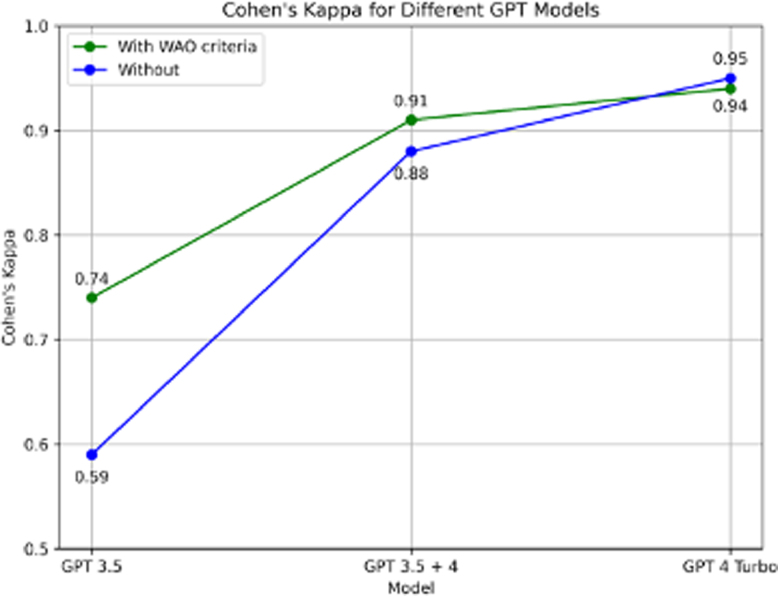
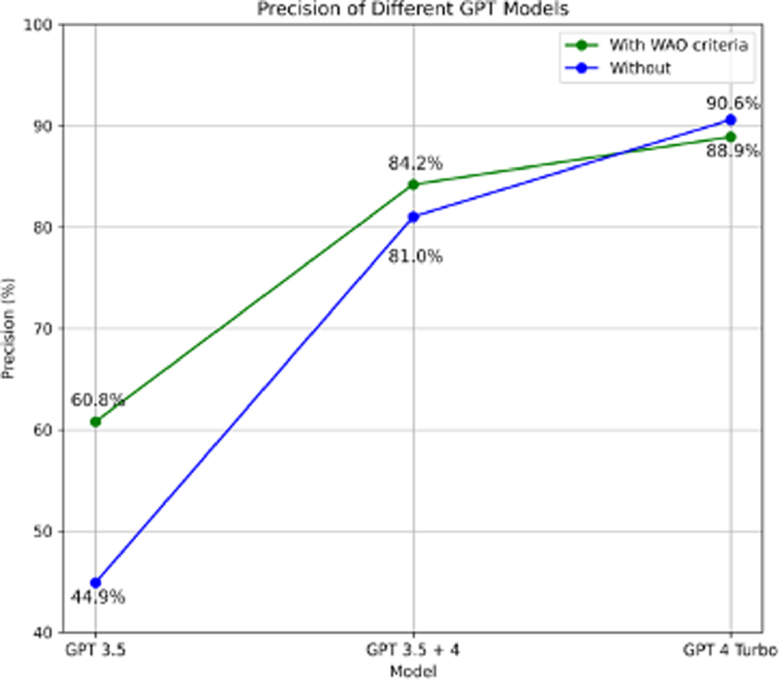
Results: Using the primary prompt, GPT 4 Turbo detected anaphylaxis cases with 90.6% precision, 100% sensitivity, 99.5% specificity, 99.5% accuracy, and a Cohen kappa coefficient of 0.95. The inclusion of WAO criteria slightly improved the performance of older models (GPT 3.5 + 4 configuration). However, for GPT 4 Turbo, additional information did not enhance precision.
Conclusion: The results highlight the potential of artificial intelligence, particularly LLMs, to automate anaphylaxis diagnosis, support healthcare professionals, and improve patient safety and care.
期刊介绍:
Asia Pacific Allergy (AP Allergy) is the official journal of the Asia Pacific Association of Allergy, Asthma and Clinical Immunology (APAAACI). Although the primary aim of the journal is to promote communication between Asia Pacific scientists who are interested in allergy, asthma, and clinical immunology including immunodeficiency, the journal is intended to be available worldwide. To enable scientists and clinicians from emerging societies appreciate the scope and intent of the journal, early issues will contain more educational review material. For better communication and understanding, it will include rational concepts related to the diagnosis and management of asthma and other immunological conditions. Over time, the journal will increase the number of original research papers to become the foremost citation journal for allergy and clinical immunology information of the Asia Pacific in the future.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


