Cheng-Peng Li, Aimé Terence Kalisa, Siyer Roohani, Kamal Hummedah, Franka Menge, Christoph Reißfelder, Markus Albertsmeier, Bernd Kasper, Jens Jakob, Cui Yang
{"title":"The imitation game: large language models versus multidisciplinary tumor boards: benchmarking AI against 21 sarcoma centers from the ring trial.","authors":"Cheng-Peng Li, Aimé Terence Kalisa, Siyer Roohani, Kamal Hummedah, Franka Menge, Christoph Reißfelder, Markus Albertsmeier, Bernd Kasper, Jens Jakob, Cui Yang","doi":"10.1007/s00432-025-06304-9","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>The study aims to compare the treatment recommendations generated by four leading large language models (LLMs) with those from 21 sarcoma centers' multidisciplinary tumor boards (MTBs) of the sarcoma ring trial in managing complex soft tissue sarcoma (STS) cases.</p><p><strong>Methods: </strong>We simulated STS-MTBs using four LLMs-Llama 3.2-vison: 90b, Claude 3.5 Sonnet, DeepSeek-R1, and OpenAI-o1 across five anonymized STS cases from the sarcoma ring trial. Each model was queried 21 times per case using a standardized prompt, and the responses were compared with human MTBs in terms of intra-model consistency, treatment recommendation alignment, alternative recommendations, and source citation.</p><p><strong>Results: </strong>LLMs demonstrated high inter-model and intra-model consistency in only 20% of cases, and their recommendations aligned with human consensus in only 20-60% of cases. The model with the highest concordance with the most common MTB recommendation, Claude 3.5 Sonnet, aligned with experts in only 60% of cases. Notably, the recommendations across MTBs were highly heterogenous, contextualizing the variable LLM performance. Discrepancies were particularly notable, where common human recommendations were often absent in LLM outputs. Additionally, the sources for the recommendation rationale of LLMs were clearly derived from the German S3 sarcoma guidelines in only 24.8% to 55.2% of the responses. LLMs occasionally suggested potentially harmful information were also observed in alternative recommendations.</p><p><strong>Conclusions: </strong>Despite the considerable heterogeneity observed in MTB recommendations, the significant discrepancies and potentially harmful recommendations highlight current AI tools' limitations, underscoring that referral to high-volume sarcoma centers remains essential for optimal patient care. At the same time, LLMs could serve as an excellent tool to prepare for MDT discussions.</p>","PeriodicalId":15118,"journal":{"name":"Journal of Cancer Research and Clinical Oncology","volume":"151 9","pages":"248"},"PeriodicalIF":2.8000,"publicationDate":"2025-09-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12420562/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Cancer Research and Clinical Oncology","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1007/s00432-025-06304-9","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"ONCOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Purpose: The study aims to compare the treatment recommendations generated by four leading large language models (LLMs) with those from 21 sarcoma centers' multidisciplinary tumor boards (MTBs) of the sarcoma ring trial in managing complex soft tissue sarcoma (STS) cases.
Methods: We simulated STS-MTBs using four LLMs-Llama 3.2-vison: 90b, Claude 3.5 Sonnet, DeepSeek-R1, and OpenAI-o1 across five anonymized STS cases from the sarcoma ring trial. Each model was queried 21 times per case using a standardized prompt, and the responses were compared with human MTBs in terms of intra-model consistency, treatment recommendation alignment, alternative recommendations, and source citation.
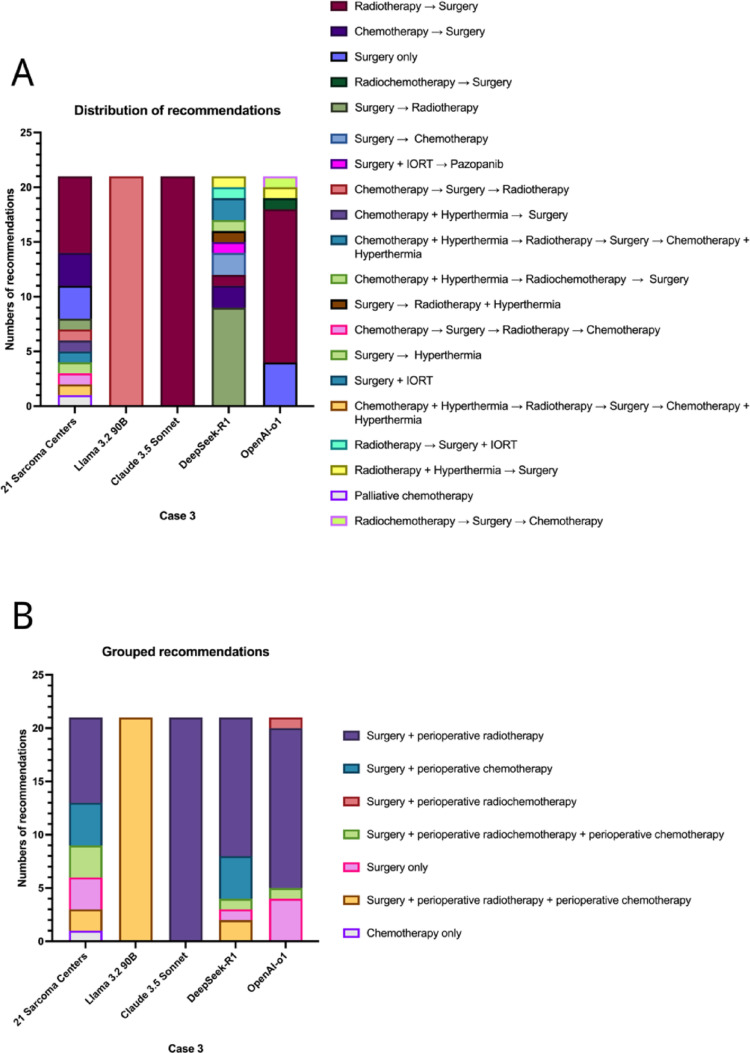
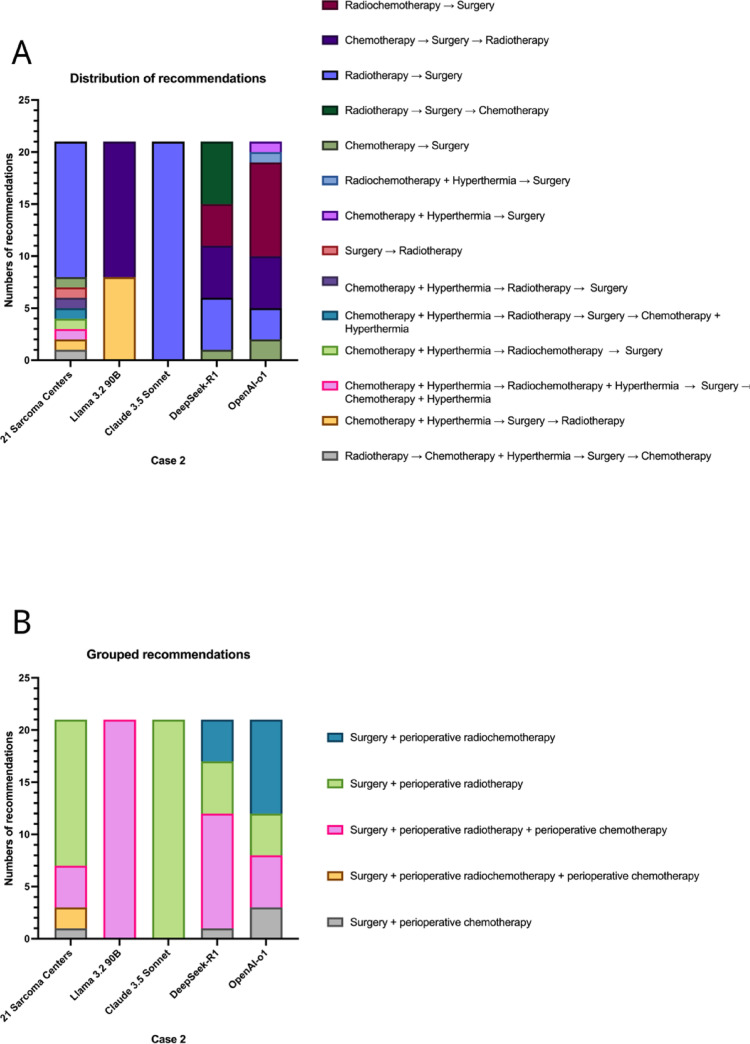
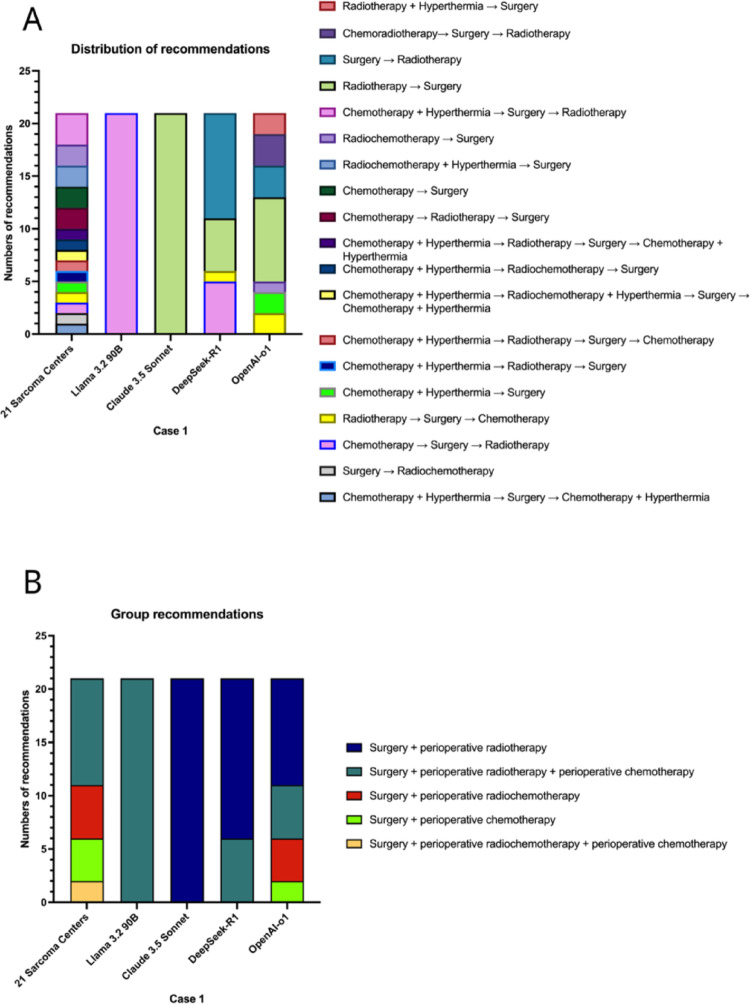
Results: LLMs demonstrated high inter-model and intra-model consistency in only 20% of cases, and their recommendations aligned with human consensus in only 20-60% of cases. The model with the highest concordance with the most common MTB recommendation, Claude 3.5 Sonnet, aligned with experts in only 60% of cases. Notably, the recommendations across MTBs were highly heterogenous, contextualizing the variable LLM performance. Discrepancies were particularly notable, where common human recommendations were often absent in LLM outputs. Additionally, the sources for the recommendation rationale of LLMs were clearly derived from the German S3 sarcoma guidelines in only 24.8% to 55.2% of the responses. LLMs occasionally suggested potentially harmful information were also observed in alternative recommendations.
Conclusions: Despite the considerable heterogeneity observed in MTB recommendations, the significant discrepancies and potentially harmful recommendations highlight current AI tools' limitations, underscoring that referral to high-volume sarcoma centers remains essential for optimal patient care. At the same time, LLMs could serve as an excellent tool to prepare for MDT discussions.
期刊介绍:
The "Journal of Cancer Research and Clinical Oncology" publishes significant and up-to-date articles within the fields of experimental and clinical oncology. The journal, which is chiefly devoted to Original papers, also includes Reviews as well as Editorials and Guest editorials on current, controversial topics. The section Letters to the editors provides a forum for a rapid exchange of comments and information concerning previously published papers and topics of current interest. Meeting reports provide current information on the latest results presented at important congresses.
The following fields are covered: carcinogenesis - etiology, mechanisms; molecular biology; recent developments in tumor therapy; general diagnosis; laboratory diagnosis; diagnostic and experimental pathology; oncologic surgery; and epidemiology.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


