Physics-guided human interaction generation via motion diffusion model
IF 3.5
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
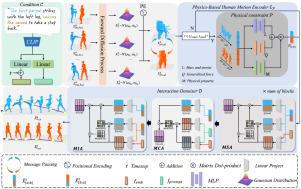
Denoising diffusion model significantly boosts the generation of two-person interactions conditioned on textual descriptions. However, due to the complexity of interactions and the diversity of textual descriptions, motion generation still faces two critical challenges: The self-induced motion and the increasing error accumulation with more denoised steps. To address these issues, we propose a novel Physics-guided human Interaction generation framework based on motion diffusion model, named PhyInter. It can synthesize contextually appropriate motion, automatically learn the dynamic states of the other participant without additional annotation, and also optimize the errors of generation by guiding the next denoising diffusion step. Specifically, PhyInter integrates physical principles from two perspectives: (1) Defining a stochastic differential equation based on human kinematics to model the physical states of interaction; (2) Employing an interactive attention module to share physical information between intra- and inter-human motions. Additionally, we design a sampling strategy to facilitate motion generation and avoid unnecessary computation, ensuring realistic, physically-plausible interactions. Extensive experiments demonstrate that our method surpasses previous approaches on the InterHuman dataset, achieving the state-of-the-art performance.
通过运动扩散模型生成物理引导的人类互动
去噪扩散模型显著促进了以文本描述为条件的两人交互的生成。然而,由于相互作用的复杂性和文本描述的多样性,运动生成仍然面临两个关键挑战:自诱导运动和随着降噪步骤的增加而增加的误差积累。为了解决这些问题,我们提出了一个新的基于运动扩散模型的物理指导的人类互动生成框架,命名为PhyInter。它可以合成上下文合适的运动,自动学习其他参与者的动态状态,而无需额外的注释,并通过指导下一个去噪扩散步骤来优化生成的误差。具体来说,PhyInter从两个角度整合了物理原理:(1)定义基于人体运动学的随机微分方程来模拟相互作用的物理状态;(2)采用交互式注意模块,在人体内和人之间的动作之间共享物理信息。此外,我们设计了一种采样策略,以促进运动生成,避免不必要的计算,确保现实的,物理上合理的交互。大量的实验表明,我们的方法超越了以前在InterHuman数据集上的方法,实现了最先进的性能。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Computer Vision and Image Understanding
工程技术-工程:电子与电气
CiteScore
7.80
自引率
4.40%
发文量
112
审稿时长
79 days
期刊介绍:
The central focus of this journal is the computer analysis of pictorial information. Computer Vision and Image Understanding publishes papers covering all aspects of image analysis from the low-level, iconic processes of early vision to the high-level, symbolic processes of recognition and interpretation. A wide range of topics in the image understanding area is covered, including papers offering insights that differ from predominant views.
Research Areas Include:
• Theory
• Early vision
• Data structures and representations
• Shape
• Range
• Motion
• Matching and recognition
• Architecture and languages
• Vision systems
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


