Juliana Damasio Oliveira, Henrique D P Santos, Ana Helena D P S Ulbrich, Julia Colleoni Couto, Marcelo Arocha, Joaquim Santos, Manuela Martins Costa, Daniela Faccio, Fabio O Tabalipa, Rodrigo F Nogueira
{"title":"Development and evaluation of a clinical note summarization system using large language models.","authors":"Juliana Damasio Oliveira, Henrique D P Santos, Ana Helena D P S Ulbrich, Julia Colleoni Couto, Marcelo Arocha, Joaquim Santos, Manuela Martins Costa, Daniela Faccio, Fabio O Tabalipa, Rodrigo F Nogueira","doi":"10.1038/s43856-025-01091-3","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Clinical notes are a vital and detailed source of information about patient hospitalizations. However, the sheer volume and complexity of these notes make evaluation and summarization challenging. Nonetheless, summarizing clinical notes is essential for accurate and efficient clinical decision-making in patient care. Generative language models, particularly large language models such as GPT-4, offer a promising solution by creating coherent, contextually relevant text based on patterns learned from large datasets.</p><p><strong>Methods: </strong>This study describes the development of a discharge summary system using large language models. By conducting an online survey and interviews, we gather feedback from end users, including physicians and patients, to ensure the system meets their practical needs and fits their experiences. Additionally, we develop a rating system to evaluate prompt effectiveness by comparing model-generated outputs with human assessments, which serve as benchmarks to evaluate the performance of the automated model.</p><p><strong>Results: </strong>Here we show that the model's ability to interpret diagnoses borders on humanlevel accuracy, demonstrating its potential to assist healthcare professionals in routine tasks such as generating discharge summaries.</p><p><strong>Conclusions: </strong>This advancement underscores the potential of large language models in clinical settings and opens up possibilities for broader applications in healthcare documentation and decision-making support.</p>","PeriodicalId":72646,"journal":{"name":"Communications medicine","volume":"5 1","pages":"376"},"PeriodicalIF":5.4000,"publicationDate":"2025-08-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12394402/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Communications medicine","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1038/s43856-025-01091-3","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MEDICINE, RESEARCH & EXPERIMENTAL","Score":null,"Total":0}
引用次数: 0
Abstract
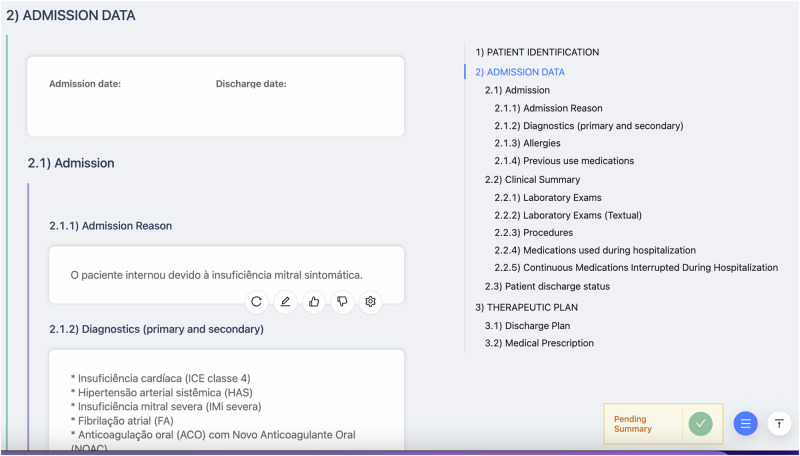
Background: Clinical notes are a vital and detailed source of information about patient hospitalizations. However, the sheer volume and complexity of these notes make evaluation and summarization challenging. Nonetheless, summarizing clinical notes is essential for accurate and efficient clinical decision-making in patient care. Generative language models, particularly large language models such as GPT-4, offer a promising solution by creating coherent, contextually relevant text based on patterns learned from large datasets.
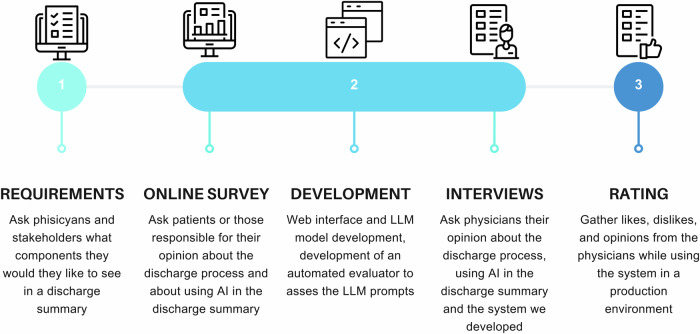
Methods: This study describes the development of a discharge summary system using large language models. By conducting an online survey and interviews, we gather feedback from end users, including physicians and patients, to ensure the system meets their practical needs and fits their experiences. Additionally, we develop a rating system to evaluate prompt effectiveness by comparing model-generated outputs with human assessments, which serve as benchmarks to evaluate the performance of the automated model.
Results: Here we show that the model's ability to interpret diagnoses borders on humanlevel accuracy, demonstrating its potential to assist healthcare professionals in routine tasks such as generating discharge summaries.
Conclusions: This advancement underscores the potential of large language models in clinical settings and opens up possibilities for broader applications in healthcare documentation and decision-making support.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


