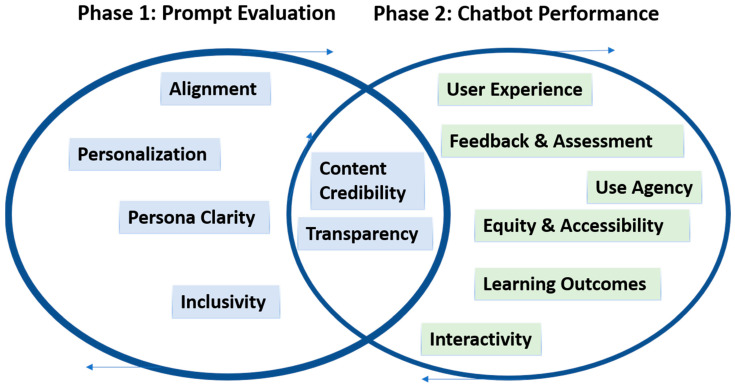
{"title":"Beyond the Bot: A Dual-Phase Framework for Evaluating AI Chatbot Simulations in Nursing Education.","authors":"Phillip Olla, Nadine Wodwaski, Taylor Long","doi":"10.3390/nursrep15080280","DOIUrl":null,"url":null,"abstract":"<p><p><b>Background/Objectives:</b> The integration of AI chatbots in nursing education, particularly in simulation-based learning, is advancing rapidly. However, there is a lack of structured evaluation models, especially to assess AI-generated simulations. This article introduces the AI-Integrated Method for Simulation (AIMS) evaluation framework, a dual-phase evaluation framework adapted from the FAITA model, designed to evaluate both prompt design and chatbot performance in the context of nursing education. <b>Methods:</b> This simulation-based study explored the application of an AI chatbot in an emergency planning course. The AIMS framework was developed and applied, consisting of six prompt-level domains (Phase 1) and eight performance criteria (Phase 2). These domains were selected based on current best practices in instructional design, simulation fidelity, and emerging AI evaluation literature. To assess the chatbots educational utility, the study employed a scoring rubric for each phase and incorporated a structured feedback loop to refine both prompt design and chatbox interaction. To demonstrate the framework's practical application, the researchers configured an AI tool referred to in this study as \"Eval-Bot v1\", built using OpenAI's GPT-4.0, to apply Phase 1 scoring criteria to a real simulation prompt. Insights from this analysis were then used to anticipate Phase 2 performance and identify areas for improvement. Participants (three individuals)-all experienced healthcare educators and advanced practice nurses with expertise in clinical decision-making and simulation-based teaching-reviewed the prompt and Eval-Bot's score to triangulate findings. <b>Results:</b> Simulated evaluations revealed clear strengths in the prompt alignment with course objectives and its capacity to foster interactive learning. Participants noted that the AI chatbot supported engagement and maintained appropriate pacing, particularly in scenarios involving emergency planning decision-making. However, challenges emerged in areas related to personalization and inclusivity. While the chatbot responded consistently to general queries, it struggled to adapt tone, complexity and content to reflect diverse learner needs or cultural nuances. To support replication and refinement, a sample scoring rubric and simulation prompt template are provided. When evaluated using the Eval-Bot tool, moderate concerns were flagged regarding safety prompts and inclusive language, particularly in how the chatbot navigated sensitive decision points. These gaps were linked to predicted performance issues in Phase 2 domains such as dialog control, equity, and user reassurance. Based on these findings, revised prompt strategies were developed to improve contextual sensitivity, promote inclusivity, and strengthen ethical guidance within chatbot-led simulations. <b>Conclusions:</b> The AIMS evaluation framework provides a practical and replicable approach for evaluating the use of AI chatbots in simulation-based education. By offering structured criteria for both prompt design and chatbot performance, the model supports instructional designers, simulation specialists, and developers in identifying areas of strength and improvement. The findings underscore the importance of intentional design, safety monitoring, and inclusive language when integrating AI into nursing and health education. As AI tools become more embedded in learning environments, this framework offers a thoughtful starting point for ensuring they are applied ethically, effectively, and with learner diversity in mind.</p>","PeriodicalId":40753,"journal":{"name":"Nursing Reports","volume":"15 8","pages":""},"PeriodicalIF":2.0000,"publicationDate":"2025-07-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12389130/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nursing Reports","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3390/nursrep15080280","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"NURSING","Score":null,"Total":0}
引用次数: 0
Abstract
Background/Objectives: The integration of AI chatbots in nursing education, particularly in simulation-based learning, is advancing rapidly. However, there is a lack of structured evaluation models, especially to assess AI-generated simulations. This article introduces the AI-Integrated Method for Simulation (AIMS) evaluation framework, a dual-phase evaluation framework adapted from the FAITA model, designed to evaluate both prompt design and chatbot performance in the context of nursing education. Methods: This simulation-based study explored the application of an AI chatbot in an emergency planning course. The AIMS framework was developed and applied, consisting of six prompt-level domains (Phase 1) and eight performance criteria (Phase 2). These domains were selected based on current best practices in instructional design, simulation fidelity, and emerging AI evaluation literature. To assess the chatbots educational utility, the study employed a scoring rubric for each phase and incorporated a structured feedback loop to refine both prompt design and chatbox interaction. To demonstrate the framework's practical application, the researchers configured an AI tool referred to in this study as "Eval-Bot v1", built using OpenAI's GPT-4.0, to apply Phase 1 scoring criteria to a real simulation prompt. Insights from this analysis were then used to anticipate Phase 2 performance and identify areas for improvement. Participants (three individuals)-all experienced healthcare educators and advanced practice nurses with expertise in clinical decision-making and simulation-based teaching-reviewed the prompt and Eval-Bot's score to triangulate findings. Results: Simulated evaluations revealed clear strengths in the prompt alignment with course objectives and its capacity to foster interactive learning. Participants noted that the AI chatbot supported engagement and maintained appropriate pacing, particularly in scenarios involving emergency planning decision-making. However, challenges emerged in areas related to personalization and inclusivity. While the chatbot responded consistently to general queries, it struggled to adapt tone, complexity and content to reflect diverse learner needs or cultural nuances. To support replication and refinement, a sample scoring rubric and simulation prompt template are provided. When evaluated using the Eval-Bot tool, moderate concerns were flagged regarding safety prompts and inclusive language, particularly in how the chatbot navigated sensitive decision points. These gaps were linked to predicted performance issues in Phase 2 domains such as dialog control, equity, and user reassurance. Based on these findings, revised prompt strategies were developed to improve contextual sensitivity, promote inclusivity, and strengthen ethical guidance within chatbot-led simulations. Conclusions: The AIMS evaluation framework provides a practical and replicable approach for evaluating the use of AI chatbots in simulation-based education. By offering structured criteria for both prompt design and chatbot performance, the model supports instructional designers, simulation specialists, and developers in identifying areas of strength and improvement. The findings underscore the importance of intentional design, safety monitoring, and inclusive language when integrating AI into nursing and health education. As AI tools become more embedded in learning environments, this framework offers a thoughtful starting point for ensuring they are applied ethically, effectively, and with learner diversity in mind.
期刊介绍:
Nursing Reports is an open access, peer-reviewed, online-only journal that aims to influence the art and science of nursing by making rigorously conducted research accessible and understood to the full spectrum of practicing nurses, academics, educators and interested members of the public. The journal represents an exhilarating opportunity to make a unique and significant contribution to nursing and the wider community by addressing topics, theories and issues that concern the whole field of Nursing Science, including research, practice, policy and education. The primary intent of the journal is to present scientifically sound and influential empirical and theoretical studies, critical reviews and open debates to the global community of nurses. Short reports, opinions and insight into the plight of nurses the world-over will provide a voice for those of all cultures, governments and perspectives. The emphasis of Nursing Reports will be on ensuring that the highest quality of evidence and contribution is made available to the greatest number of nurses. Nursing Reports aims to make original, evidence-based, peer-reviewed research available to the global community of nurses and to interested members of the public. In addition, reviews of the literature, open debates on professional issues and short reports from around the world are invited to contribute to our vibrant and dynamic journal. All published work will adhere to the most stringent ethical standards and journalistic principles of fairness, worth and credibility. Our journal publishes Editorials, Original Articles, Review articles, Critical Debates, Short Reports from Around the Globe and Letters to the Editor.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


