{"title":"AI-Driven Large Language Models in Health Consultations for HIV Patients.","authors":"Chun-Yan Zhao, Chang Song, Tong Yang, Ai-Chun Huang, Hang-Biao Qiang, Chun-Ming Gong, Jing-Song Chen, Qing-Dong Zhu","doi":"10.2147/JMDH.S533621","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>This study endeavors to conduct a comprehensive assessment on the performance of large language models (LLMs) in health consultation for individuals living with HIV, delve into their applicability across a diverse array of dimensions, and provide evidence-based support for clinical deployment.</p><p><strong>Patients and methods: </strong>A 23-question multi-dimensional HIV-specific question bank was developed, covering fundamental knowledge, diagnosis, treatment, prognosis, and case analysis. Four advanced LLMs-ChatGPT-4o, Copilot, Gemini, and Claude-were tested using a multi-dimensional evaluation system assessing medical accuracy, comprehensiveness, understandability, reliability, and humanistic care (which encompasses elements such as individual needs attention, emotional support, and ethical considerations). A five-point Likert scale was employed, with three experts independently scoring. Statistical metrics (mean, standard deviation, standard error) were calculated, followed by consistency analysis, difference analysis, and post-hoc testing.</p><p><strong>Results: </strong>Claude obtained the most outstanding performance with regard to information comprehensiveness (mean score 4.333), understandability (mean score 3.797), and humanistic care (mean score 2.855); Copilot demonstrated proficiency in diagnostic questions (mean score 3.880); Gemini illustrated exceptional performance in case analysis (mean score 4.111). Based on the post-hoc analysis, Claude outperformed other models in thoroughness and humanistic care (P < 0.05). Copilot showed better performance than ChatGPT in understandability (P = 0.045), while Gemini performed significantly better than ChatGPT in case analysis (P < 0.001). It is important to note that performance varied across tasks, and humanistic care remained a consistent weak point across all models.</p><p><strong>Conclusion: </strong>The superiority of diverse models in specific tasks suggest that LLMs hold extensive application potential in the management of HIV patients. Nevertheless, their efficacy in the realm of humanistic care still needs improvement.</p>","PeriodicalId":16357,"journal":{"name":"Journal of Multidisciplinary Healthcare","volume":"18 ","pages":"5187-5198"},"PeriodicalIF":2.4000,"publicationDate":"2025-08-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12396217/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Multidisciplinary Healthcare","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2147/JMDH.S533621","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Purpose: This study endeavors to conduct a comprehensive assessment on the performance of large language models (LLMs) in health consultation for individuals living with HIV, delve into their applicability across a diverse array of dimensions, and provide evidence-based support for clinical deployment.
Patients and methods: A 23-question multi-dimensional HIV-specific question bank was developed, covering fundamental knowledge, diagnosis, treatment, prognosis, and case analysis. Four advanced LLMs-ChatGPT-4o, Copilot, Gemini, and Claude-were tested using a multi-dimensional evaluation system assessing medical accuracy, comprehensiveness, understandability, reliability, and humanistic care (which encompasses elements such as individual needs attention, emotional support, and ethical considerations). A five-point Likert scale was employed, with three experts independently scoring. Statistical metrics (mean, standard deviation, standard error) were calculated, followed by consistency analysis, difference analysis, and post-hoc testing.
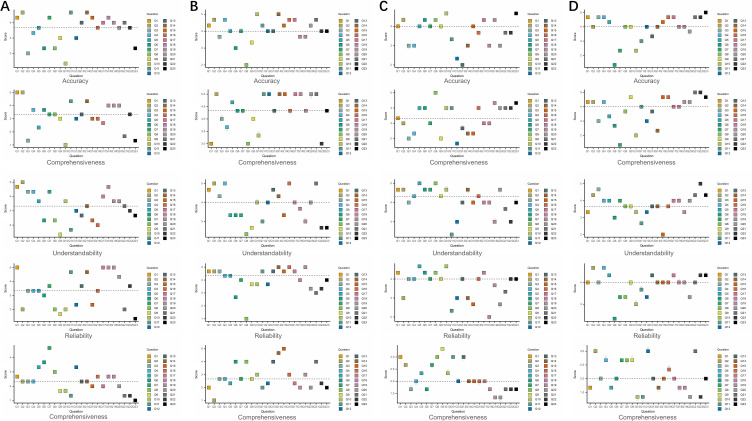
Results: Claude obtained the most outstanding performance with regard to information comprehensiveness (mean score 4.333), understandability (mean score 3.797), and humanistic care (mean score 2.855); Copilot demonstrated proficiency in diagnostic questions (mean score 3.880); Gemini illustrated exceptional performance in case analysis (mean score 4.111). Based on the post-hoc analysis, Claude outperformed other models in thoroughness and humanistic care (P < 0.05). Copilot showed better performance than ChatGPT in understandability (P = 0.045), while Gemini performed significantly better than ChatGPT in case analysis (P < 0.001). It is important to note that performance varied across tasks, and humanistic care remained a consistent weak point across all models.
Conclusion: The superiority of diverse models in specific tasks suggest that LLMs hold extensive application potential in the management of HIV patients. Nevertheless, their efficacy in the realm of humanistic care still needs improvement.
期刊介绍:
The Journal of Multidisciplinary Healthcare (JMDH) aims to represent and publish research in healthcare areas delivered by practitioners of different disciplines. This includes studies and reviews conducted by multidisciplinary teams as well as research which evaluates or reports the results or conduct of such teams or healthcare processes in general. The journal covers a very wide range of areas and we welcome submissions from practitioners at all levels and from all over the world. Good healthcare is not bounded by person, place or time and the journal aims to reflect this. The JMDH is published as an open-access journal to allow this wide range of practical, patient relevant research to be immediately available to practitioners who can access and use it immediately upon publication.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


