Assessing the impact of tuning parameter in instance selection based bug resolution classification
IF 4.3
2区 计算机科学
Q2 COMPUTER SCIENCE, INFORMATION SYSTEMS
引用次数: 0
Abstract
Context
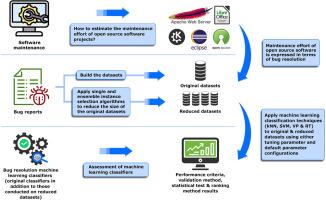
Software maintenance is time-consuming and requires significant effort for bug resolution and various types of software enhancement. Estimating software maintenance effort is challenging for open source software (OSS) without historical data about direct effort expressed in terms of man-days, compared to proprietary software for which this data about effort is available. Therefore, maintenance efforts in the OSS context can only be estimated indirectly through other features, such as OSS bug reports, and other approaches, such as bug resolution prediction models using a number of machine learning (ML) techniques. Although these bug reports are at times large in size, they need to be preprocessed before they can be used. In this context, instance selection (IS) has been presented in the literature as a way of reducing the size of datasets by selecting a subset of instances. Additionally, ML techniques often require fine-tuning of numerous parameters to achieve optimal predictions. This is typically done using tuning parameter (TP) methods.
Objective
The empirical study reported here investigated the impact of TP methods together with instance selection algorithms (ISAs) on the performance of bug resolution prediction ML classifiers on five datasets: Eclipse JDT, Eclipse Platform, KDE, LibreOffice, and Apache.
Method
To this end, a set of 480 ML classifiers are built using 60 datasets including the five original ones, 15 reduced datasets using Edited Nearest Neighbor (ENN), Repeated Edited Nearest Neighbor (RENN), and all-k Nearest Neighbor (AllkNN) single ISAs, and 40 reduced datasets using Bagging, Random Feature Subsets, and Voting ensemble ISAs, together with four ML techniques (k Nearest Neighbor (kNN), Support Vector Machine (SVM), Voted Perceptron (VP), and Random Tree (RT) using Grid Search (GS) and Default Parameter (DP) configurations. Furthermore, the classifiers were evaluated using Accuracy, Precision, and Recall performance criteria, in addition to the ten-fold cross-validation method. Next, these classifiers are compared to determine how parameter tuning and IS can enhance bug resolution prediction performance.
Conclusion
The findings revealed that (1) using GS with single ISAs enhanced the performance of the built ML classifiers, (2) using GS with homogeneous and heterogeneous ensemble ISAs enhanced the performance of the built ML classifiers, and (3) associating GS and SVM with RENN (either used as a single ISA or implemented as a base algorithm for ensemble ISAs) gave the best performance.
评估基于错误解决分类的实例选择中调优参数的影响
软件维护非常耗时,需要大量的精力来解决错误和各种类型的软件增强。对于没有以人-天表示的直接工作的历史数据的开源软件(OSS)来说,评估软件维护工作是具有挑战性的,而对于专有软件来说,这些工作的数据是可用的。因此,OSS环境中的维护工作只能通过其他特性间接地估计,例如OSS错误报告,以及其他方法,例如使用许多机器学习(ML)技术的错误解决预测模型。尽管这些错误报告有时很大,但在使用它们之前需要对它们进行预处理。在这种情况下,实例选择(IS)在文献中被认为是一种通过选择实例子集来减少数据集大小的方法。此外,机器学习技术通常需要对许多参数进行微调以实现最佳预测。这通常是使用调优参数(TP)方法完成的。在Eclipse JDT、Eclipse Platform、KDE、LibreOffice和Apache 5个数据集上,研究TP方法与实例选择算法(ISAs)对bug解决预测ML分类器性能的影响。为此,使用60个数据集构建了480个ML分类器,其中包括5个原始数据集,15个使用编辑近邻(ENN)、重复编辑近邻(RENN)和全k近邻(AllkNN)单个ISAs的约简数据集,以及40个使用Bagging、随机特征子集和投票集成ISAs的约简数据集,以及4种ML技术(k近邻(kNN)、支持向量机(SVM)、投票感知器(VP)、和随机树(RT)使用网格搜索(GS)和默认参数(DP)配置。此外,除了十倍交叉验证方法外,分类器还使用准确性,精密度和召回率性能标准进行评估。接下来,对这些分类器进行比较,以确定参数调优和IS如何提高bug解决预测性能。结论研究结果表明:(1)将GS与单个ISA结合使用可以提高所构建机器学习分类器的性能;(2)将GS与同质和异构集成ISA结合使用可以提高所构建机器学习分类器的性能;(3)将GS和SVM与RENN(无论是作为单个ISA还是作为集成ISA的基础算法)相结合,效果最好。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Information and Software Technology
工程技术-计算机:软件工程
CiteScore
9.10
自引率
7.70%
发文量
164
审稿时长
9.6 weeks
期刊介绍:
Information and Software Technology is the international archival journal focusing on research and experience that contributes to the improvement of software development practices. The journal''s scope includes methods and techniques to better engineer software and manage its development. Articles submitted for review should have a clear component of software engineering or address ways to improve the engineering and management of software development. Areas covered by the journal include:
• Software management, quality and metrics,
• Software processes,
• Software architecture, modelling, specification, design and programming
• Functional and non-functional software requirements
• Software testing and verification & validation
• Empirical studies of all aspects of engineering and managing software development
Short Communications is a new section dedicated to short papers addressing new ideas, controversial opinions, "Negative" results and much more. Read the Guide for authors for more information.
The journal encourages and welcomes submissions of systematic literature studies (reviews and maps) within the scope of the journal. Information and Software Technology is the premiere outlet for systematic literature studies in software engineering.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


