Adaptive mesh-aligned Gaussian Splatting for monocular human avatar reconstruction
IF 2.2
4区 计算机科学
Q2 COMPUTER SCIENCE, SOFTWARE ENGINEERING
引用次数: 0
Abstract
Virtual human avatars are essential for applications such as gaming, augmented reality, and virtual production. However, existing methods struggle to achieve high fidelity reconstruction from monocular input while keeping hardware costs low. Many approaches rely on the SMPL body prior and apply vertex offsets to represent clothed avatars. Unfortunately, excessive offsets often cause misalignment and blurred contours, particularly around clothing wrinkles, silhouette boundaries, and facial regions. To address these limitations, we propose a dual branch framework for human avatar reconstruction from monocular video. A lightweight Vertex Align Net (VAN) predicts per-vertex normal direction offsets on the SMPL mesh to achieve coarse geometric alignment and guide Gaussian-based human avatar modeling. In parallel, we construct a high resolution facial Gaussian branch based on FLAME estimated parameters, with facial regions localized via pretrained detectors. The facial and body renderings are fused using a semantic mask to enhance facial clarity and ensure globally consistent avatar appearance. Experiments demonstrate that our method surpasses state of the art approaches in modeling animatable human avatars with fine grained fidelity.
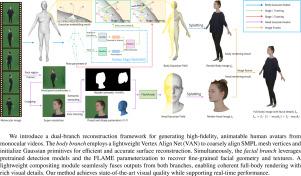
自适应网格对齐高斯飞溅单目人体头像重建
虚拟的人类化身对于游戏、增强现实和虚拟生产等应用是必不可少的。然而,现有的方法很难从单目输入实现高保真重建,同时保持低硬件成本。许多方法依赖于SMPL主体,并应用顶点偏移来表示穿着衣服的角色。不幸的是,过度的偏移往往会导致轮廓不一致和模糊,特别是在衣服褶皱、轮廓边界和面部区域。为了解决这些限制,我们提出了一个双分支框架,用于从单目视频中重建人类头像。一个轻量级的顶点对齐网络(VAN)预测SMPL网格上的每个顶点法线方向偏移,以实现粗几何对齐并指导基于高斯的人类化身建模。同时,我们基于FLAME估计参数构建了一个高分辨率的面部高斯分支,并通过预训练的检测器对面部区域进行了定位。面部和身体渲染融合使用语义掩码,以增强面部清晰度,并确保全球一致的化身外观。实验表明,我们的方法在建模具有细粒度保真度的可动画人类化身方面超越了最先进的方法。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Graphical Models
工程技术-计算机:软件工程
CiteScore
3.60
自引率
5.90%
发文量
15
审稿时长
47 days
期刊介绍:
Graphical Models is recognized internationally as a highly rated, top tier journal and is focused on the creation, geometric processing, animation, and visualization of graphical models and on their applications in engineering, science, culture, and entertainment. GMOD provides its readers with thoroughly reviewed and carefully selected papers that disseminate exciting innovations, that teach rigorous theoretical foundations, that propose robust and efficient solutions, or that describe ambitious systems or applications in a variety of topics.
We invite papers in five categories: research (contributions of novel theoretical or practical approaches or solutions), survey (opinionated views of the state-of-the-art and challenges in a specific topic), system (the architecture and implementation details of an innovative architecture for a complete system that supports model/animation design, acquisition, analysis, visualization?), application (description of a novel application of know techniques and evaluation of its impact), or lecture (an elegant and inspiring perspective on previously published results that clarifies them and teaches them in a new way).
GMOD offers its authors an accelerated review, feedback from experts in the field, immediate online publication of accepted papers, no restriction on color and length (when justified by the content) in the online version, and a broad promotion of published papers. A prestigious group of editors selected from among the premier international researchers in their fields oversees the review process.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


