Christopher Bowd, Akram Belghith, Mark Christopher, Makoto Araie, Aiko Iwase, Goji Tomita, Kyoko Ohno-Matsui, Hitomi Saito, Hiroshi Murata, Tsutomu Kikawa, Kazuhisa Sugiyama, Tomomi Higashide, Atsuya Miki, Toru Nakazawa, Makoto Aihara, Tae-Woo Kim, Christopher Kai Shun Leung, Robert N Weinreb, Linda M Zangwill
{"title":"Glaucoma detection in myopic eyes using deep learning autoencoder-based regions of interest.","authors":"Christopher Bowd, Akram Belghith, Mark Christopher, Makoto Araie, Aiko Iwase, Goji Tomita, Kyoko Ohno-Matsui, Hitomi Saito, Hiroshi Murata, Tsutomu Kikawa, Kazuhisa Sugiyama, Tomomi Higashide, Atsuya Miki, Toru Nakazawa, Makoto Aihara, Tae-Woo Kim, Christopher Kai Shun Leung, Robert N Weinreb, Linda M Zangwill","doi":"10.3389/fopht.2025.1624015","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>To evaluate the diagnostic accuracy of a deep learning autoencoder-based model utilizing regions of interest (ROI) from optical coherence tomography (OCT) texture enface images for detecting glaucoma in myopic eyes.</p><p><strong>Methods: </strong>This cross-sectional study included a total of 453 eyes from 315 participants from the multi-center \"Swept-Source OCT (SS-OCT) Myopia and Glaucoma Study\", composed of 268 eyes from 168 healthy individuals and 185 eyes from 147 glaucomatous individuals. All participants underwent swept-source optical coherence tomography (SS-OCT) imaging, from which texture enface images were constructed and analyzed. The study compared four methods: (1) global RNFL thickness, (2) texture enface image, (3) a single autoencoder model trained only on healthy eyes, and (4) a dual autoencoder model trained on both healthy and glaucomatous eyes. Diagnostic accuracy was assessed using the area under the receiver operating curves (AUROC) and precision recall curves (AUPRC).</p><p><strong>Results: </strong>The dual autoencoder model achieved the highest AUROC (95% CI) (0.92 [0.88, 0.95]), significantly outperforming the single autoencoder model trained only on healthy eyes (0.86 [0.83, 0.88], p = 0.01), the global RNFL thickness model (0.84 [0.80, 0.86], p = 0.003), and the texture enface model (0.83 [0.79, 0.85], p = 0.005). Using AUPRC (95% CI), the dual autoencoder model (0.86 [0.83, 0.89]) also outperformed the single autoencoder model trained only on healthy eyes (0.80 [0.78, 0.82], p = 0.02), the global RNFL thickness model (0.74 [0.70, 0.76], p = 0.001), and the texture enface model (0.71 [0.68, 0.73], p<0.001). No significant difference was observed between the global RNFL thickness measurement and the texture enface measurement (p = 0.47).</p><p><strong>Discussion: </strong>The dual autoencoder model, which integrates reconstruction errors from both healthy and glaucomatous training data, demonstrated superior diagnostic accuracy compared to the single autoencoder model, global RNFL thickness and texture enface-based approaches. These findings suggest that deep learning models leveraging ROI-based reconstruction error from texture enface images may enhance glaucoma classification in myopic eyes, providing a robust alternative to conventional structural thickness metrics.</p>","PeriodicalId":73096,"journal":{"name":"Frontiers in ophthalmology","volume":"5 ","pages":"1624015"},"PeriodicalIF":0.9000,"publicationDate":"2025-08-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12358265/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in ophthalmology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fopht.2025.1624015","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Purpose: To evaluate the diagnostic accuracy of a deep learning autoencoder-based model utilizing regions of interest (ROI) from optical coherence tomography (OCT) texture enface images for detecting glaucoma in myopic eyes.
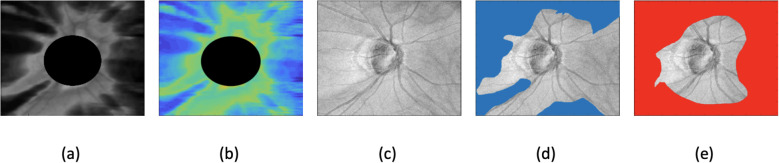
Methods: This cross-sectional study included a total of 453 eyes from 315 participants from the multi-center "Swept-Source OCT (SS-OCT) Myopia and Glaucoma Study", composed of 268 eyes from 168 healthy individuals and 185 eyes from 147 glaucomatous individuals. All participants underwent swept-source optical coherence tomography (SS-OCT) imaging, from which texture enface images were constructed and analyzed. The study compared four methods: (1) global RNFL thickness, (2) texture enface image, (3) a single autoencoder model trained only on healthy eyes, and (4) a dual autoencoder model trained on both healthy and glaucomatous eyes. Diagnostic accuracy was assessed using the area under the receiver operating curves (AUROC) and precision recall curves (AUPRC).
Results: The dual autoencoder model achieved the highest AUROC (95% CI) (0.92 [0.88, 0.95]), significantly outperforming the single autoencoder model trained only on healthy eyes (0.86 [0.83, 0.88], p = 0.01), the global RNFL thickness model (0.84 [0.80, 0.86], p = 0.003), and the texture enface model (0.83 [0.79, 0.85], p = 0.005). Using AUPRC (95% CI), the dual autoencoder model (0.86 [0.83, 0.89]) also outperformed the single autoencoder model trained only on healthy eyes (0.80 [0.78, 0.82], p = 0.02), the global RNFL thickness model (0.74 [0.70, 0.76], p = 0.001), and the texture enface model (0.71 [0.68, 0.73], p<0.001). No significant difference was observed between the global RNFL thickness measurement and the texture enface measurement (p = 0.47).
Discussion: The dual autoencoder model, which integrates reconstruction errors from both healthy and glaucomatous training data, demonstrated superior diagnostic accuracy compared to the single autoencoder model, global RNFL thickness and texture enface-based approaches. These findings suggest that deep learning models leveraging ROI-based reconstruction error from texture enface images may enhance glaucoma classification in myopic eyes, providing a robust alternative to conventional structural thickness metrics.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


