Jakub Pristoupil, Laura Oleaga, Vanesa Junquero, Cristina Merino, Suha Sureyya Ozbek, Lukas Lambert
{"title":"Five advanced chatbots solving European Diploma in Radiology (EDiR) text-based questions: differences in performance and consistency.","authors":"Jakub Pristoupil, Laura Oleaga, Vanesa Junquero, Cristina Merino, Suha Sureyya Ozbek, Lukas Lambert","doi":"10.1186/s41747-025-00591-0","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>We compared the performance, confidence, and response consistency of five chatbots powered by large language models in solving European Diploma in Radiology (EDiR) text-based multiple-response questions.</p><p><strong>Methods: </strong>ChatGPT-4o, ChatGPT-4o-mini, Copilot, Gemini, and Claude 3.5 Sonnet were tested using 52 text-based multiple-response questions from two previous EDiR sessions in two iterations. Chatbots were prompted to evaluate each answer as correct or incorrect and grade its confidence level on a scale of 0 (not confident at all) to 10 (most confident). Scores per question were calculated using a weighted formula that accounted for correct and incorrect answers (range 0.0-1.0).</p><p><strong>Results: </strong>Claude 3.5 Sonnet achieved the highest score per question (0.84 ± 0.26, mean ± standard deviation) compared to ChatGPT-4o (0.76 ± 0.31), ChatGPT-4o-mini (0.64 ± 0.35), Copilot (0.62 ± 0.37), and Gemini (0.54 ± 0.39) (p < 0.001). A self-reported confidence in answering the questions was 9.0 ± 0.9 for Claude 3.5 Sonnet followed by ChatGPT-4o (8.7 ± 1.1), compared to ChatGPT-4o-mini (8.2 ± 1.3), Copilot (8.2 ± 2.2), and Gemini (8.2 ± 1.6, p < 0.001). Claude 3.5 Sonnet demonstrated superior consistency, changing responses in 5.4% of cases between the two iterations, compared to ChatGPT-4o (6.5%), ChatGPT-4o-mini (8.8%), Copilot (13.8%), and Gemini (18.5%). All chatbots outperformed human candidates from previous EDiR sessions, achieving a passing grade from this part of the examination.</p><p><strong>Conclusion: </strong>Claude 3.5 Sonnet exhibited superior accuracy, confidence, and consistency, with ChatGPT-4o performing nearly as well. The variation in performance among the evaluated models was substantial.</p><p><strong>Relevance statement: </strong>Variation in performance, consistency, and confidence among chatbots in solving EDiR test-based questions highlights the need for cautious deployment, particularly in high-stakes clinical and educational settings.</p><p><strong>Key points: </strong>Claude 3.5 Sonnet outperformed other chatbots in accuracy and response consistency. ChatGPT-4o ranked second, showing strong but slightly less reliable performance. All chatbots surpassed EDiR candidates in text-based EDiR questions.</p>","PeriodicalId":36926,"journal":{"name":"European Radiology Experimental","volume":"9 1","pages":"79"},"PeriodicalIF":3.6000,"publicationDate":"2025-08-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12364795/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"European Radiology Experimental","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s41747-025-00591-0","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING","Score":null,"Total":0}
引用次数: 0
Abstract
Background: We compared the performance, confidence, and response consistency of five chatbots powered by large language models in solving European Diploma in Radiology (EDiR) text-based multiple-response questions.
Methods: ChatGPT-4o, ChatGPT-4o-mini, Copilot, Gemini, and Claude 3.5 Sonnet were tested using 52 text-based multiple-response questions from two previous EDiR sessions in two iterations. Chatbots were prompted to evaluate each answer as correct or incorrect and grade its confidence level on a scale of 0 (not confident at all) to 10 (most confident). Scores per question were calculated using a weighted formula that accounted for correct and incorrect answers (range 0.0-1.0).
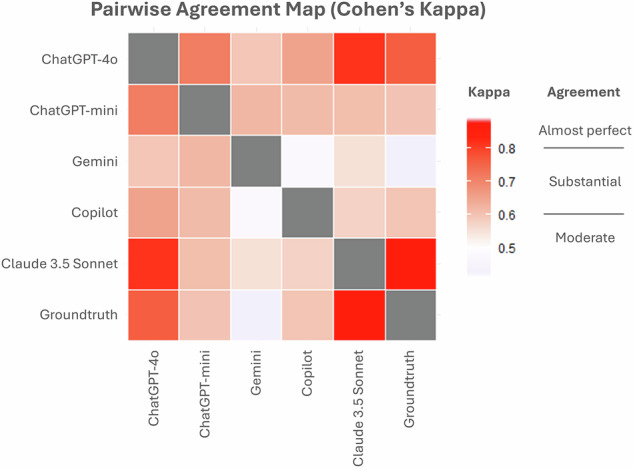
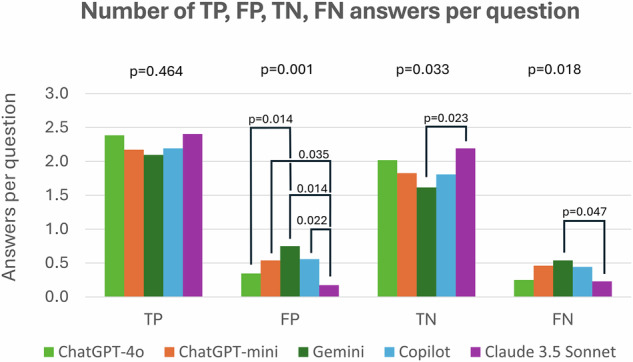
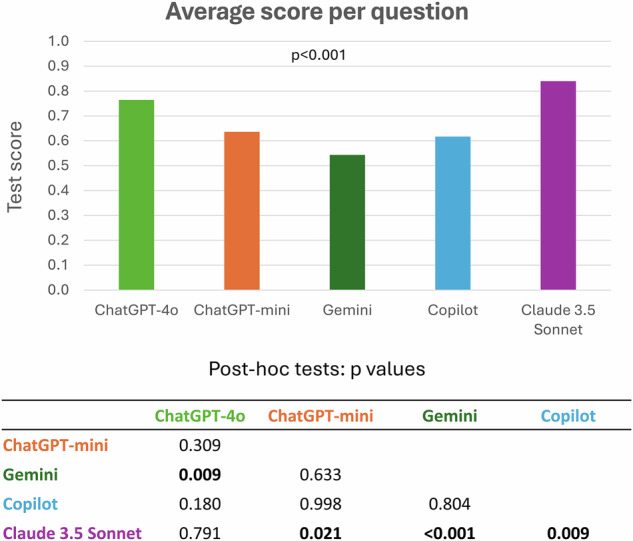
Results: Claude 3.5 Sonnet achieved the highest score per question (0.84 ± 0.26, mean ± standard deviation) compared to ChatGPT-4o (0.76 ± 0.31), ChatGPT-4o-mini (0.64 ± 0.35), Copilot (0.62 ± 0.37), and Gemini (0.54 ± 0.39) (p < 0.001). A self-reported confidence in answering the questions was 9.0 ± 0.9 for Claude 3.5 Sonnet followed by ChatGPT-4o (8.7 ± 1.1), compared to ChatGPT-4o-mini (8.2 ± 1.3), Copilot (8.2 ± 2.2), and Gemini (8.2 ± 1.6, p < 0.001). Claude 3.5 Sonnet demonstrated superior consistency, changing responses in 5.4% of cases between the two iterations, compared to ChatGPT-4o (6.5%), ChatGPT-4o-mini (8.8%), Copilot (13.8%), and Gemini (18.5%). All chatbots outperformed human candidates from previous EDiR sessions, achieving a passing grade from this part of the examination.
Conclusion: Claude 3.5 Sonnet exhibited superior accuracy, confidence, and consistency, with ChatGPT-4o performing nearly as well. The variation in performance among the evaluated models was substantial.
Relevance statement: Variation in performance, consistency, and confidence among chatbots in solving EDiR test-based questions highlights the need for cautious deployment, particularly in high-stakes clinical and educational settings.
Key points: Claude 3.5 Sonnet outperformed other chatbots in accuracy and response consistency. ChatGPT-4o ranked second, showing strong but slightly less reliable performance. All chatbots surpassed EDiR candidates in text-based EDiR questions.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


