Enhancing fashion e-commerce retrieval: A self-supervised graph-integrated framework for cross-modal image–text alignment
IF 6.8
2区 工程技术
Q1 ENGINEERING, MULTIDISCIPLINARY
引用次数: 0
Abstract
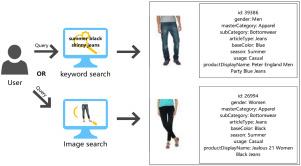
Cross-modal retrieval is pivotal for enhancing user experiences in the rapidly evolving fashion e-commerce sector. However, conventional methods often struggle with fine-grained feature alignment and maintaining modal consistency. To overcome these challenges, we propose G-SimX, an innovative framework that synergizes self-supervised contrastive learning via SimCLR with Graph Convolutional Networks (GCN) for robust cross-modal image–text retrieval. By harnessing SimCLR, G-SimX significantly reduces reliance on annotated data, while the integration of GCN facilitates structured relational modeling to capture intricate semantic associations between product images and textual descriptions. Extensive experiments on the FashionGenAttnGAN dataset demonstrate that G-SimX achieves outstanding mAP scores of 0.856 for image-to-text and 0.842 for text-to-image retrieval—improving upon the CLIP baseline by over 20%. Moreover, our approach exhibits exceptional stability with reduced training loss fluctuations (0.161 vs. 0.189) and markedly enhanced robustness against data perturbations (0.92 vs. 0.76). Ablation studies further affirm the contributions of each module, revealing mAP drops of 11.7% and 16.9% upon removing SimCLR and GCN, respectively. With a convergence rate 95.8% faster than existing methods, G-SimX offers a scalable and efficient solution for real-world fashion e-commerce applications.
增强时尚电子商务检索:用于跨模态图像-文本对齐的自监督图形集成框架
在快速发展的时尚电子商务领域,跨模式检索对于增强用户体验至关重要。然而,传统的方法经常在细粒度特征对齐和保持模态一致性方面遇到困难。为了克服这些挑战,我们提出了G-SimX,这是一个创新的框架,通过SimCLR将自监督对比学习与图卷积网络(GCN)协同起来,实现鲁棒的跨模态图像-文本检索。通过利用SimCLR, G-SimX显著减少了对注释数据的依赖,而GCN的集成促进了结构化关系建模,以捕获产品图像和文本描述之间复杂的语义关联。在FashionGenAttnGAN数据集上进行的大量实验表明,G-SimX在图像到文本检索方面取得了0.856的优异mAP分数,在文本到图像检索方面取得了0.842的优异分数,在CLIP基线上提高了20%以上。此外,我们的方法表现出优异的稳定性,减少了训练损失波动(0.161 vs. 0.189),显著增强了对数据扰动的鲁棒性(0.92 vs. 0.76)。消融研究进一步证实了每个模块的贡献,发现去除SimCLR和GCN后,mAP分别下降了11.7%和16.9%。G-SimX的收敛速度比现有方法快95.8%,为现实世界的时尚电子商务应用提供了可扩展和高效的解决方案。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

alexandria engineering journal
Engineering-General Engineering
CiteScore
11.20
自引率
4.40%
发文量
1015
审稿时长
43 days
期刊介绍:
Alexandria Engineering Journal is an international journal devoted to publishing high quality papers in the field of engineering and applied science. Alexandria Engineering Journal is cited in the Engineering Information Services (EIS) and the Chemical Abstracts (CA). The papers published in Alexandria Engineering Journal are grouped into five sections, according to the following classification:
• Mechanical, Production, Marine and Textile Engineering
• Electrical Engineering, Computer Science and Nuclear Engineering
• Civil and Architecture Engineering
• Chemical Engineering and Applied Sciences
• Environmental Engineering
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


