Thijs Veugen, Vincent Dunning, Michiel Marcus, Bart Kamphorst
{"title":"Secure latent Dirichlet allocation.","authors":"Thijs Veugen, Vincent Dunning, Michiel Marcus, Bart Kamphorst","doi":"10.3389/fdgth.2025.1610228","DOIUrl":null,"url":null,"abstract":"<p><p>Topic modelling refers to a popular set of techniques used to discover hidden topics that occur in a collection of documents. These topics can, for example, be used to categorize documents or label text for further processing. One popular topic modelling technique is Latent Dirichlet Allocation (LDA). In topic modelling scenarios, the documents are often assumed to be in one, centralized dataset. However, sometimes documents are held by different parties, and contain privacy- or commercially-sensitive information that cannot be shared. We present a novel, decentralized approach to train an LDA model securely without having to share any information about the content of the documents. We preserve the privacy of the individual parties using a combination of privacy enhancing technologies. Next to the secure LDA protocol, we introduce two new cryptographic building blocks that are of independent interest; a way to efficiently convert between secret-shared- and homomorphic-encrypted data as well as a method to efficiently draw a random number from a finite set with secret weights. We show that our decentralized, privacy preserving LDA solution has a similar accuracy compared to an (insecure) centralised approach. With 1024-bit Paillier keys, a topic model with 5 topics and 3000 words can be trained in around 16 h. Furthermore, we show that the solution scales linearly in the total number of words and the number of topics.</p>","PeriodicalId":73078,"journal":{"name":"Frontiers in digital health","volume":"7 ","pages":"1610228"},"PeriodicalIF":3.2000,"publicationDate":"2025-07-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12328381/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fdgth.2025.1610228","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
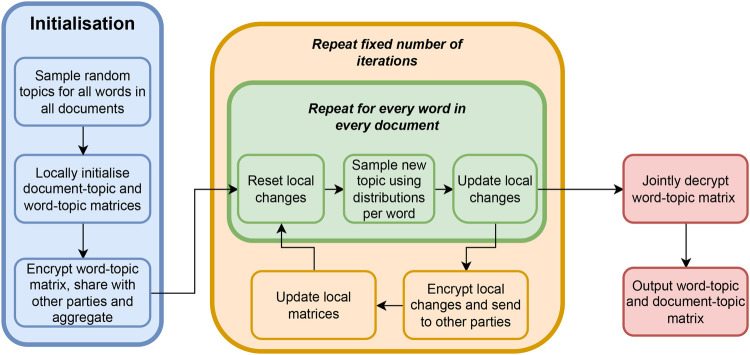
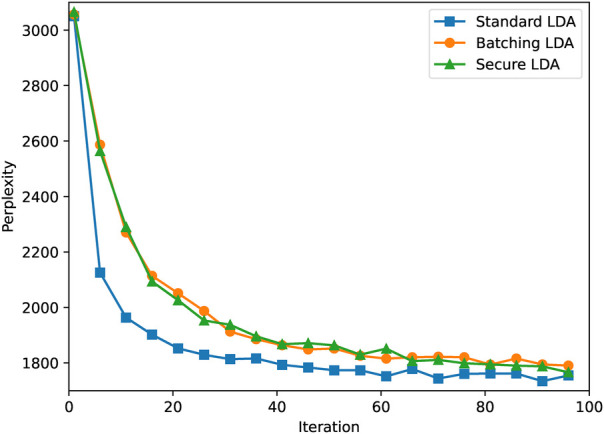
Topic modelling refers to a popular set of techniques used to discover hidden topics that occur in a collection of documents. These topics can, for example, be used to categorize documents or label text for further processing. One popular topic modelling technique is Latent Dirichlet Allocation (LDA). In topic modelling scenarios, the documents are often assumed to be in one, centralized dataset. However, sometimes documents are held by different parties, and contain privacy- or commercially-sensitive information that cannot be shared. We present a novel, decentralized approach to train an LDA model securely without having to share any information about the content of the documents. We preserve the privacy of the individual parties using a combination of privacy enhancing technologies. Next to the secure LDA protocol, we introduce two new cryptographic building blocks that are of independent interest; a way to efficiently convert between secret-shared- and homomorphic-encrypted data as well as a method to efficiently draw a random number from a finite set with secret weights. We show that our decentralized, privacy preserving LDA solution has a similar accuracy compared to an (insecure) centralised approach. With 1024-bit Paillier keys, a topic model with 5 topics and 3000 words can be trained in around 16 h. Furthermore, we show that the solution scales linearly in the total number of words and the number of topics.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


