Yi-Lin Wang, Li-Chao Tian, Jing-Yuan Meng, Jie-Chao Zhang, Zhi-Xing Nie, Wen-Rui Wei, Dao-Fang Ding, Xiao-Ye Tang, Qian Zhang, Yong He
{"title":"Evaluation of large language models in patient education and clinical decision support for rotator cuff injury: a two-phase benchmarking study.","authors":"Yi-Lin Wang, Li-Chao Tian, Jing-Yuan Meng, Jie-Chao Zhang, Zhi-Xing Nie, Wen-Rui Wei, Dao-Fang Ding, Xiao-Ye Tang, Qian Zhang, Yong He","doi":"10.1186/s12911-025-03105-5","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>This study evaluates the accuracy of ChatGPT-4o, ChatGPT-o1, Gemini, and ERNIE Bot in answering rotator cuff injury questions and responding to patients. Results show Gemini excels in accuracy, while ChatGPT-4o performs better in patient interactions.</p><p><strong>Methods: </strong>Phase 1: Four LLM chatbots answered physician test questions on rotator cuff injuries, interacting with patients and students. Their performance was assessed for accuracy and clarity across 108 multiple-choice and 20 clinical questions. Phase 2: Twenty patients questioned the top two chatbots (ChatGPT-4o, Gemini), with responses rated for satisfaction and readability. Three physicians evaluated accuracy, usefulness, safety, and completeness using a 5-point Likert scale. Statistical analyses and plotting used IBM SPSS 29.0.1.0 and Prism 10; Friedman test compared evaluation and readability scores among chatbots with Bonferroni-corrected pairwise comparisons, Mann-Whitney U test compared ChatGPT-4o versus Gemini; statistical significance at p < 0.05.</p><p><strong>Results: </strong>Gemini achieved the highest average accuracy. In the second part, Gemini showed the highest proficiency in answering rotator cuff injury-related queries (accuracy: 4.70; completeness: 4.72; readability: 4.70; usefulness: 4.61; safety: 4.70, post hoc Dunnett test, p < 0.05). Additionally, 20 rotator cuff injury patients questioned the top two models from Phase 1 (ChatGPT-4o and Gemini). ChatGPT-4o had the highest reading difficulty score (14.22, post hoc Dunnett test, p < 0.05), suggesting a middle school reading level or above. Statistical analysis showed significant differences in patient satisfaction (4.52 vs. 3.76, p < 0.001) and readability (4.35 vs. 4.23). Orthopedic surgeons rated ChatGPT-4o higher in accuracy, completeness, readability, usefulness, and safety (all p < 0.05), outperforming Gemini in all aspects.</p><p><strong>Conclusion: </strong>The study found that LLMs, particularly ChatGPT-4o and Gemini, excelled in understanding rotator cuff injury-related knowledge and responding to patients, showing strong potential for further development.</p>","PeriodicalId":9340,"journal":{"name":"BMC Medical Informatics and Decision Making","volume":"25 1","pages":"289"},"PeriodicalIF":3.8000,"publicationDate":"2025-08-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12323112/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMC Medical Informatics and Decision Making","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1186/s12911-025-03105-5","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
Objective: This study evaluates the accuracy of ChatGPT-4o, ChatGPT-o1, Gemini, and ERNIE Bot in answering rotator cuff injury questions and responding to patients. Results show Gemini excels in accuracy, while ChatGPT-4o performs better in patient interactions.
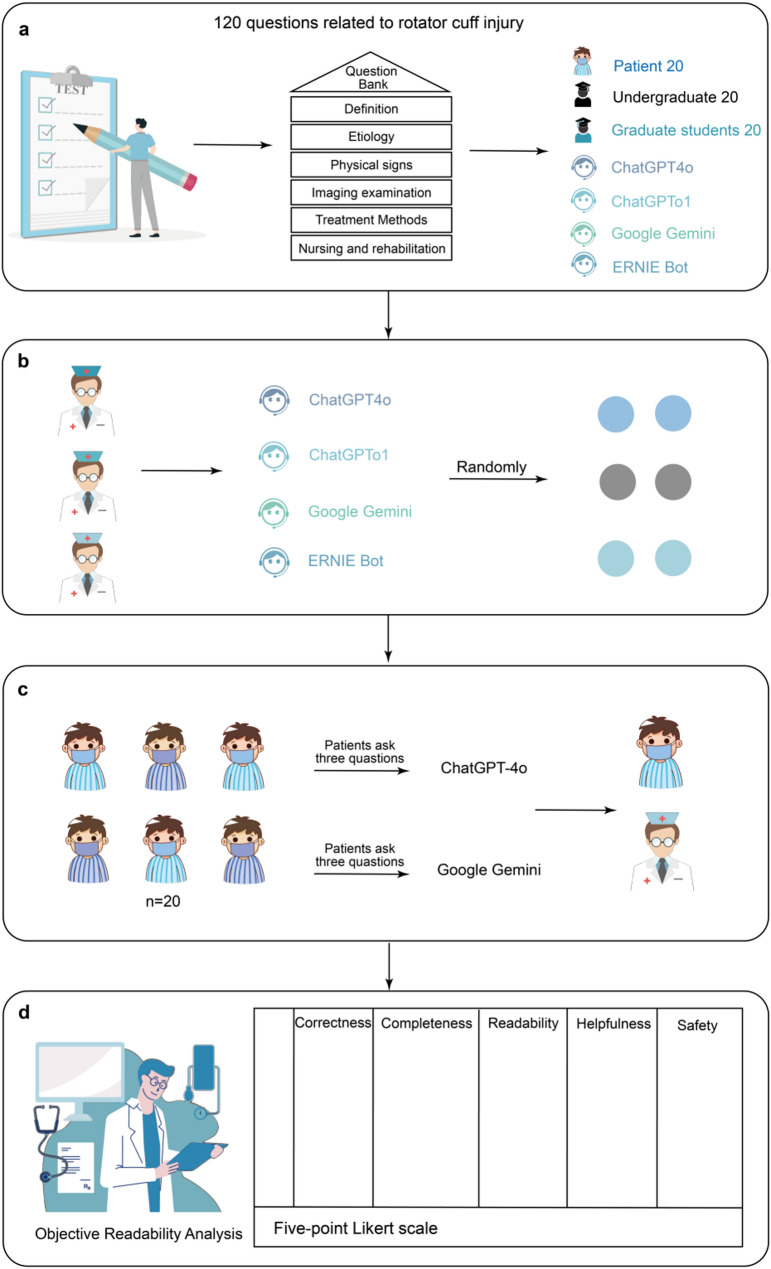
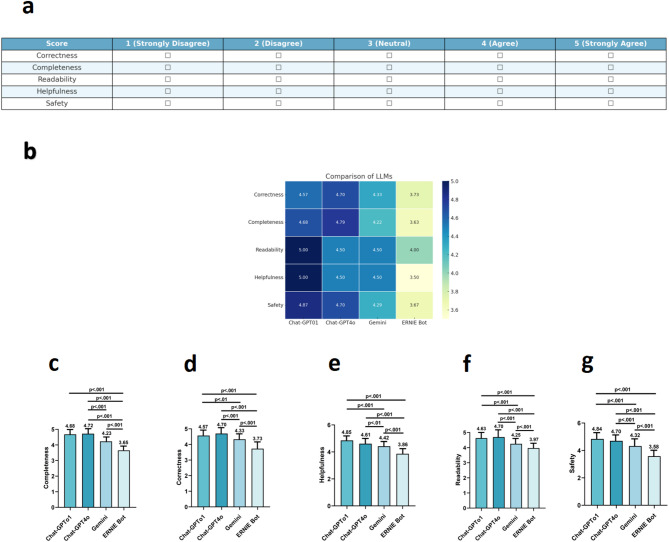
Methods: Phase 1: Four LLM chatbots answered physician test questions on rotator cuff injuries, interacting with patients and students. Their performance was assessed for accuracy and clarity across 108 multiple-choice and 20 clinical questions. Phase 2: Twenty patients questioned the top two chatbots (ChatGPT-4o, Gemini), with responses rated for satisfaction and readability. Three physicians evaluated accuracy, usefulness, safety, and completeness using a 5-point Likert scale. Statistical analyses and plotting used IBM SPSS 29.0.1.0 and Prism 10; Friedman test compared evaluation and readability scores among chatbots with Bonferroni-corrected pairwise comparisons, Mann-Whitney U test compared ChatGPT-4o versus Gemini; statistical significance at p < 0.05.
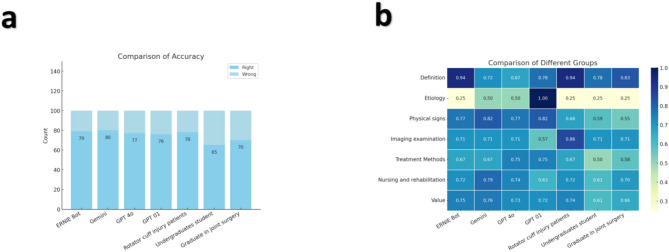
Results: Gemini achieved the highest average accuracy. In the second part, Gemini showed the highest proficiency in answering rotator cuff injury-related queries (accuracy: 4.70; completeness: 4.72; readability: 4.70; usefulness: 4.61; safety: 4.70, post hoc Dunnett test, p < 0.05). Additionally, 20 rotator cuff injury patients questioned the top two models from Phase 1 (ChatGPT-4o and Gemini). ChatGPT-4o had the highest reading difficulty score (14.22, post hoc Dunnett test, p < 0.05), suggesting a middle school reading level or above. Statistical analysis showed significant differences in patient satisfaction (4.52 vs. 3.76, p < 0.001) and readability (4.35 vs. 4.23). Orthopedic surgeons rated ChatGPT-4o higher in accuracy, completeness, readability, usefulness, and safety (all p < 0.05), outperforming Gemini in all aspects.
Conclusion: The study found that LLMs, particularly ChatGPT-4o and Gemini, excelled in understanding rotator cuff injury-related knowledge and responding to patients, showing strong potential for further development.
期刊介绍:
BMC Medical Informatics and Decision Making is an open access journal publishing original peer-reviewed research articles in relation to the design, development, implementation, use, and evaluation of health information technologies and decision-making for human health.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


