{"title":"Performance of AI Models vs. Orthopedic Residents in Turkish Specialty Training Development Exams in Orthopedics.","authors":"Enver Ipek, Yusuf Sulek, Bahadir Balkanli","doi":"10.14744/SEMB.2025.65289","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>As artificial intelligence (AI) continues to advance, its integration into medical education and clinical decision making has attracted considerable attention. Large language models, such as ChatGPT-4o, Gemini, Bing AI, and DeepSeek, have demonstrated potential in supporting healthcare professionals, particularly in specialty training examinations. However, the extent to which these models can independently match or surpass human performance in specialized medical assessments remains uncertain. This study aimed to systematically compare the performance of these AI models with orthopedic residents in the Specialty Training Development Exams (UEGS) conducted between 2010 and 2021, focusing on their accuracy, depth of explanation, and clinical applicability.</p><p><strong>Methods: </strong>This retrospective comparative study involved presenting the UEGS questions to ChatGPT-4o, Gemini, Bing AI, and DeepSeek. Orthopedic residents who took the exams during 2010-2021 served as the control group. The responses were evaluated for accuracy, explanatory details, and clinical applicability. Statistical analysis was conducted using SPSS Version 27, with one-way ANOVA and post-hoc tests for performance comparison.</p><p><strong>Results: </strong>All AI models outperformed orthopedic residents in terms of accuracy. Bing AI demonstrated the highest accuracy rates (64.0% to 93.0%), followed by Gemini (66.0% to 87.0%) and DeepSeek (63.5% to 81.0%). ChatGPT-4o showed the lowest accuracy among AI models (51.0% to 59.5%). Orthopedic residents consistently had the lowest accuracy (43.95% to 53.45%). Bing AI, Gemini, and DeepSeek showed knowledge levels equivalent to over 5 years of medical experience, while ChatGPT-4o ranged from to 2-5 years.</p><p><strong>Conclusion: </strong>This study showed that AI models, especially Bing AI and Gemini, perform at a high level in orthopedic specialty examinations and have potential as educational support tools. However, the lower accuracy of ChatGPT-4o reduced its suitability for assessment. Despite these limitations, AI shows promise in medical education. Future research should focus on improving the reliability, incorporating visual data interpretation, and exploring clinical integration.</p>","PeriodicalId":42218,"journal":{"name":"Medical Bulletin of Sisli Etfal Hospital","volume":"59 2","pages":"151-155"},"PeriodicalIF":0.9000,"publicationDate":"2025-02-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12314458/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Medical Bulletin of Sisli Etfal Hospital","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.14744/SEMB.2025.65289","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"MEDICINE, GENERAL & INTERNAL","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: As artificial intelligence (AI) continues to advance, its integration into medical education and clinical decision making has attracted considerable attention. Large language models, such as ChatGPT-4o, Gemini, Bing AI, and DeepSeek, have demonstrated potential in supporting healthcare professionals, particularly in specialty training examinations. However, the extent to which these models can independently match or surpass human performance in specialized medical assessments remains uncertain. This study aimed to systematically compare the performance of these AI models with orthopedic residents in the Specialty Training Development Exams (UEGS) conducted between 2010 and 2021, focusing on their accuracy, depth of explanation, and clinical applicability.
Methods: This retrospective comparative study involved presenting the UEGS questions to ChatGPT-4o, Gemini, Bing AI, and DeepSeek. Orthopedic residents who took the exams during 2010-2021 served as the control group. The responses were evaluated for accuracy, explanatory details, and clinical applicability. Statistical analysis was conducted using SPSS Version 27, with one-way ANOVA and post-hoc tests for performance comparison.
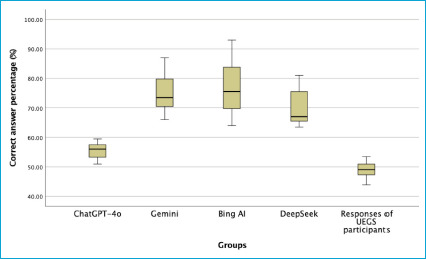
Results: All AI models outperformed orthopedic residents in terms of accuracy. Bing AI demonstrated the highest accuracy rates (64.0% to 93.0%), followed by Gemini (66.0% to 87.0%) and DeepSeek (63.5% to 81.0%). ChatGPT-4o showed the lowest accuracy among AI models (51.0% to 59.5%). Orthopedic residents consistently had the lowest accuracy (43.95% to 53.45%). Bing AI, Gemini, and DeepSeek showed knowledge levels equivalent to over 5 years of medical experience, while ChatGPT-4o ranged from to 2-5 years.
Conclusion: This study showed that AI models, especially Bing AI and Gemini, perform at a high level in orthopedic specialty examinations and have potential as educational support tools. However, the lower accuracy of ChatGPT-4o reduced its suitability for assessment. Despite these limitations, AI shows promise in medical education. Future research should focus on improving the reliability, incorporating visual data interpretation, and exploring clinical integration.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


