Text-Dominant Speech-Enhanced for Multimodal Aspect-Based Sentiment Analysis network
IF 15.5
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
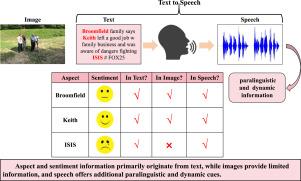
Existing Multimodal Aspect-Based Sentiment Analysis techniques primarily focus on associating visual and textual content but often overlook the critical issue of visual expression deficiency, where images fail to provide complete aspect terms and sufficient sentiment signals. To address this limitation, we propose a Multimodal Aspect-Based Sentiment Analysis network that leverages Text-Dominant Speech Enhancement (TDSEN), aiming to alleviate the deficiency in visual expression by synthesizing speech and employing a text-dominant approach. Specifically, we introduce a Text-Driven Speech Enhancement Layer that generates speech with stable timbre to identify all aspect terms, compensate for the lacking parts of visual expression, and provide additional aspect term information and emotional cues. Meanwhile, we design a semantic distance mask matrix to enhance the capability of capturing key information from the textual modality. Furthermore, a text-driven multimodal feature fusion module is incorporated to strengthen the dominant role of text and facilitate multimodal feature interaction and integration for the extraction of the term of the aspect and sentiment recognition. Comprehensive evaluations on the Twitter-2015 and Twitter-2017 benchmarks demonstrate TDSEN’s superiority, achieving absolute improvements of 2.6% and 1.7% over state-of-the-art baselines, with ablation studies confirming the necessity of each component.
文本主导语音增强的多模态面向方面的情感分析网络
现有的基于方面的多模态情感分析技术主要关注视觉和文本内容的关联,但往往忽视了视觉表达不足的关键问题,即图像不能提供完整的方面术语和足够的情感信号。为了解决这一限制,我们提出了一个利用文本主导语音增强(TDSEN)的多模态基于方面的情感分析网络,旨在通过合成语音和采用文本主导方法来缓解视觉表达的不足。具体来说,我们引入了一个文本驱动的语音增强层,该层生成具有稳定音色的语音,以识别所有方面术语,补偿视觉表达的缺失部分,并提供额外的方面术语信息和情感线索。同时,我们设计了语义距离掩码矩阵,增强了从文本模态中获取关键信息的能力。在此基础上,引入文本驱动的多模态特征融合模块,强化文本的主导作用,促进多模态特征的交互和融合,实现面向词的提取和情感识别。对Twitter-2015和Twitter-2017基准的综合评估表明,TDSEN具有优势,在最先进的基线上实现了2.6%和1.7%的绝对改进,消融研究证实了每个组件的必要性。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Information Fusion
工程技术-计算机:理论方法
CiteScore
33.20
自引率
4.30%
发文量
161
审稿时长
7.9 months
期刊介绍:
Information Fusion serves as a central platform for showcasing advancements in multi-sensor, multi-source, multi-process information fusion, fostering collaboration among diverse disciplines driving its progress. It is the leading outlet for sharing research and development in this field, focusing on architectures, algorithms, and applications. Papers dealing with fundamental theoretical analyses as well as those demonstrating their application to real-world problems will be welcome.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


