{"title":"Utility of Generative Artificial Intelligence for Japanese Medical Interview Training: Randomized Crossover Pilot Study.","authors":"Takanobu Hirosawa, Masashi Yokose, Tetsu Sakamoto, Yukinori Harada, Kazuki Tokumasu, Kazuya Mizuta, Taro Shimizu","doi":"10.2196/77332","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The medical interview remains a cornerstone of clinical training. There is growing interest in applying generative artificial intelligence (AI) in medical education, including medical interview training. However, its utility in culturally and linguistically specific contexts, including Japanese, remains underexplored. This study investigated the utility of generative AI for Japanese medical interview training.</p><p><strong>Objective: </strong>This pilot study aimed to evaluate the utility of generative AI as a tool for medical interview training by comparing its performance with that of traditional face-to-face training methods using a simulated patient.</p><p><strong>Methods: </strong>We conducted a randomized crossover pilot study involving 20 postgraduate year 1-2 physicians from a university hospital. Participants were randomly allocated into 2 groups. Group A began with an AI-based station on a case involving abdominal pain, followed by a traditional station with a standardized patient presenting chest pain. Group B followed the reverse order, starting with the traditional station for abdominal pain and subsequently within the AI-based station for the chest pain scenario. In the AI-based stations, participants interacted with a GPT-configured platform that simulated patient behaviors. GPTs are customizable versions of ChatGPT adapted for specific purposes. The traditional stations involved face-to-face interviews with a simulated patient. Both groups used identical, standardized case scenarios to ensure uniformity. Two independent evaluators, blinded to the study conditions, assessed participants' performances using 6 defined metrics: patient care and communication, history taking, physical examination, accuracy and clarity of transcription, clinical reasoning, and patient management. A 6-point Likert scale was used for scoring. The discrepancy between the evaluators was resolved through discussion. To ensure cultural and linguistic authenticity, all interviews and evaluations were conducted in Japanese.</p><p><strong>Results: </strong>AI-based stations scored lower across most categories, particularly in patient care and communication, than traditional stations (4.48 vs 4.95; P=.009). However, AI-based stations demonstrated comparable performance in clinical reasoning, with a nonsignificant difference (4.43 vs 4.85; P=.10).</p><p><strong>Conclusions: </strong>The comparable performance of generative AI in clinical reasoning highlights its potential as a complementary tool in medical interview training. One of its main advantages lies in enabling self-learning, allowing trainees to independently practice interviews without the need for simulated patients. Nonetheless, the lower scores in patient care and communication underline the importance of maintaining traditional methods that capture the nuances of human interaction. These findings support the adoption of hybrid training models that combine generative AI with conventional approaches to enhance the overall effectiveness of medical interview training in Japan.</p>","PeriodicalId":36236,"journal":{"name":"JMIR Medical Education","volume":"11 ","pages":"e77332"},"PeriodicalIF":3.2000,"publicationDate":"2025-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12316404/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Education","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/77332","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"EDUCATION, SCIENTIFIC DISCIPLINES","Score":null,"Total":0}
引用次数: 0
Abstract
Background: The medical interview remains a cornerstone of clinical training. There is growing interest in applying generative artificial intelligence (AI) in medical education, including medical interview training. However, its utility in culturally and linguistically specific contexts, including Japanese, remains underexplored. This study investigated the utility of generative AI for Japanese medical interview training.
Objective: This pilot study aimed to evaluate the utility of generative AI as a tool for medical interview training by comparing its performance with that of traditional face-to-face training methods using a simulated patient.
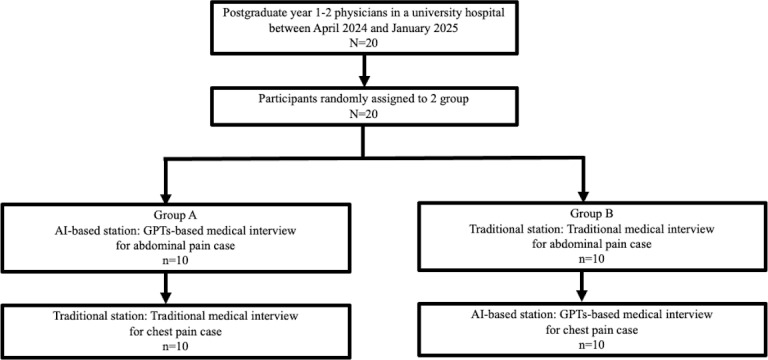
Methods: We conducted a randomized crossover pilot study involving 20 postgraduate year 1-2 physicians from a university hospital. Participants were randomly allocated into 2 groups. Group A began with an AI-based station on a case involving abdominal pain, followed by a traditional station with a standardized patient presenting chest pain. Group B followed the reverse order, starting with the traditional station for abdominal pain and subsequently within the AI-based station for the chest pain scenario. In the AI-based stations, participants interacted with a GPT-configured platform that simulated patient behaviors. GPTs are customizable versions of ChatGPT adapted for specific purposes. The traditional stations involved face-to-face interviews with a simulated patient. Both groups used identical, standardized case scenarios to ensure uniformity. Two independent evaluators, blinded to the study conditions, assessed participants' performances using 6 defined metrics: patient care and communication, history taking, physical examination, accuracy and clarity of transcription, clinical reasoning, and patient management. A 6-point Likert scale was used for scoring. The discrepancy between the evaluators was resolved through discussion. To ensure cultural and linguistic authenticity, all interviews and evaluations were conducted in Japanese.
Results: AI-based stations scored lower across most categories, particularly in patient care and communication, than traditional stations (4.48 vs 4.95; P=.009). However, AI-based stations demonstrated comparable performance in clinical reasoning, with a nonsignificant difference (4.43 vs 4.85; P=.10).
Conclusions: The comparable performance of generative AI in clinical reasoning highlights its potential as a complementary tool in medical interview training. One of its main advantages lies in enabling self-learning, allowing trainees to independently practice interviews without the need for simulated patients. Nonetheless, the lower scores in patient care and communication underline the importance of maintaining traditional methods that capture the nuances of human interaction. These findings support the adoption of hybrid training models that combine generative AI with conventional approaches to enhance the overall effectiveness of medical interview training in Japan.
背景:医学面试仍然是临床培训的基石。人们对在医学教育中应用生成式人工智能(AI)越来越感兴趣,包括医学面试培训。然而,它在包括日语在内的文化和语言特定环境中的效用仍未得到充分探索。本研究探讨了生成式人工智能在日本医学面试培训中的应用。目的:本试点研究旨在通过比较生成式人工智能与传统面对面培训方法在模拟患者中的表现,评估生成式人工智能作为医疗面试培训工具的效用。方法:我们进行了一项随机交叉试点研究,涉及20名来自某大学医院的研究生1-2年级的医生。参与者被随机分为两组。A组首先对1例腹痛患者进行人工智能站,然后对1例胸痛患者进行传统站。B组遵循相反的顺序,从传统的腹痛站开始,随后在基于人工智能的胸痛站内。在基于人工智能的工作站中,参与者与模拟患者行为的gpt配置平台进行交互。gpt是ChatGPT的可定制版本,适用于特定用途。传统的工作站包括与模拟病人面对面的访谈。两组都使用了相同的、标准化的案例场景来确保一致性。两名独立评估人员,对研究条件不知情,使用6个定义的指标评估参与者的表现:患者护理和沟通、病史记录、体格检查、转录的准确性和清晰度、临床推理和患者管理。采用6分李克特量表进行评分。通过讨论解决了评价者之间的分歧。为了确保文化和语言的真实性,所有的访谈和评估都用日语进行。结果:人工智能站在大多数类别中得分较低,特别是在患者护理和沟通方面(4.48 vs 4.95;P = .009)。然而,基于人工智能的工作站在临床推理方面表现相当,差异不显著(4.43 vs 4.85;P = 10)。结论:生成式人工智能在临床推理中的可比性表现突出了其作为医学访谈培训补充工具的潜力。它的主要优点之一是能够自我学习,允许受训者在不需要模拟病人的情况下独立练习面试。尽管如此,在病人护理和沟通方面的较低得分强调了保持捕捉人类互动细微差别的传统方法的重要性。这些发现支持采用混合培训模型,将生成式人工智能与传统方法相结合,以提高日本医疗面试培训的整体有效性。

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


