Fine-tuning large language models for interdisciplinary environmental challenges
IF 14.3
1区 环境科学与生态学
Q1 ENVIRONMENTAL SCIENCES
引用次数: 0
Abstract
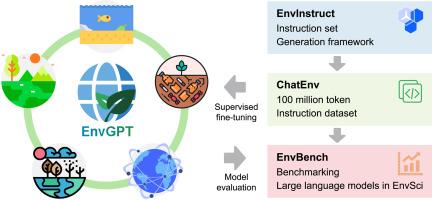
Large language models (LLMs) are revolutionizing specialized fields by enabling advanced reasoning and data synthesis. Environmental science, however, poses unique hurdles due to its interdisciplinary scope, specialized jargon, and heterogeneous data from climate dynamics to ecosystem management. Despite progress in subdomains like hydrology and climate modeling, no integrated framework exists to generate high-quality, domain-specific training data or evaluate LLM performance across the discipline. Here we introduce a unified pipeline to address this gap. It comprises EnvInstruct, a multi-agent system for prompt generation; ChatEnv, a balanced 100-million-token instruction dataset spanning five core themes (climate change, ecosystems, water resources, soil management, and renewable energy); and EnvBench, a 4998-item benchmark assessing analysis, reasoning, calculation, and description tasks. Applying this pipeline, we fine-tune an 8-billion-parameter model, EnvGPT, which achieves 92.06 ± 1.85 % accuracy on the independent EnviroExam benchmark—surpassing the parameter-matched LLaMA-3.1–8B baseline by ∼8 percentage points and rivaling the closed-source GPT-4o-mini and the 9-fold larger Qwen2.5–72B. On EnvBench, EnvGPT earns top LLM-assigned scores for relevance (4.87 ± 0.11), factuality (4.70 ± 0.15), completeness (4.38 ± 0.19), and style (4.85 ± 0.10), outperforming baselines in every category. This study reveals how targeted supervised fine-tuning on curated domain data can propel compact LLMs to state-of-the-art levels, bridging gaps in environmental applications. By openly releasing EnvGPT, ChatEnv, and EnvBench, our work establishes a reproducible foundation for accelerating LLM adoption in environmental research, policy, and practice, with potential extensions to multimodal and real-time tools.
微调大型语言模型以应对跨学科的环境挑战
大型语言模型(llm)通过实现高级推理和数据合成,正在彻底改变专业领域。然而,由于环境科学的跨学科范围、专业术语和从气候动力学到生态系统管理的异构数据,环境科学面临着独特的障碍。尽管在水文和气候建模等子领域取得了进展,但目前还没有一个集成的框架来生成高质量的、特定领域的培训数据或评估法学硕士在整个学科中的表现。这里我们引入一个统一的管道来解决这个差距。它包括envdirective,一个用于提示生成的多智能体系统;ChatEnv,一个平衡的1亿个令牌指令数据集,涵盖五个核心主题(气候变化、生态系统、水资源、土壤管理和可再生能源);EnvBench是一个4998项的基准测试,用于评估分析、推理、计算和描述任务。应用该管道,我们对80亿个参数模型EnvGPT进行了精细调整,该模型在独立的EnviroExam基准上达到92.06±1.85%的准确率,比参数匹配的LLaMA-3.1-8B基准高出约8个百分点,与闭源gpt - 40 -mini和9倍大的Qwen2.5-72B相媲美。在EnvBench上,EnvGPT在相关性(4.87±0.11),真实性(4.70±0.15),完整性(4.38±0.19)和风格(4.85±0.10)方面获得了llm分配的最高分数,在每个类别中都优于基线。这项研究揭示了如何有针对性地对策划领域数据进行监督微调,以推动紧凑的法学硕士达到最先进的水平,弥合环境应用中的差距。通过公开发布EnvGPT、ChatEnv和EnvBench,我们的工作为加速法学硕士在环境研究、政策和实践中的应用奠定了可复制的基础,并有可能扩展到多模式和实时工具。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Environmental Science and Ecotechnology
Multiple-
CiteScore
20.40
自引率
6.30%
发文量
11
审稿时长
18 days
期刊介绍:
Environmental Science & Ecotechnology (ESE) is an international, open-access journal publishing original research in environmental science, engineering, ecotechnology, and related fields. Authors publishing in ESE can immediately, permanently, and freely share their work. They have license options and retain copyright. Published by Elsevier, ESE is co-organized by the Chinese Society for Environmental Sciences, Harbin Institute of Technology, and the Chinese Research Academy of Environmental Sciences, under the supervision of the China Association for Science and Technology.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


