Dorian Garin, Stéphane Cook, Charlie Ferry, Wesley Bennar, Mario Togni, Pascal Meier, Peter Wenaweser, Serban Puricel, Diego Arroyo
{"title":"Improving large language models accuracy for aortic stenosis treatment via Heart Team simulation: a prompt design analysis.","authors":"Dorian Garin, Stéphane Cook, Charlie Ferry, Wesley Bennar, Mario Togni, Pascal Meier, Peter Wenaweser, Serban Puricel, Diego Arroyo","doi":"10.1093/ehjdh/ztaf068","DOIUrl":null,"url":null,"abstract":"<p><strong>Aims: </strong>Large language models (LLMs) have shown potential in clinical decision support, but the influence of prompt design on their performance, particularly in complex cardiology decision-making, is not well understood.</p><p><strong>Methods and results: </strong>We retrospectively reviewed 231 patients evaluated by our Heart Team for severe aortic stenosis, with treatment options including surgical aortic valve replacement, transcatheter aortic valve implantation, or medical therapy. We tested multiple prompt-design strategies using zero-shot (0-shot), Chain-of-Thought (CoT), and Tree-of-Thought (ToT) prompting, combined with few-shot prompting, free/guided-thinking, and self-consistency. Patient data were condensed into standardized vignettes and queried using GPT4-o (version 2024-05-13, OpenAI) 40 times per patient under each prompt (147 840 total queries). Primary endpoint was mean accuracy; secondary endpoints included sensitivity, specificity, area under the curve (AUC), and treatment invasiveness. Guided-thinking-ToT achieved the highest accuracy (94.04%, 95% CI 90.87-97.21), significantly outperforming few-shot-ToT (87.16%, 95% CI 82.68-91.63) and few-shot-CoT (85.32%, 95% CI 80.59-90.06; <i>P</i> < 0.0001). Zero-shot prompting showed the lowest accuracy (73.39%, 95% CI 67.48-79.31). Guided-thinking-ToT yielded the highest AUC values (up to 0.97) and was the only prompt whose invasiveness did not differ significantly from Heart Team decisions (<i>P</i> = 0.078). An inverted quadratic relationship emerged between few-shot examples and accuracy, with nine examples optimal (<i>P</i> < 0.0001). Self-consistency improved overall accuracy, particularly for ToT-derived prompts (<i>P</i> < 0.001).</p><p><strong>Conclusion: </strong>Prompt design significantly impacts LLM performance in clinical decision-making for severe aortic stenosis. Tree-of-Thought prompting markedly improved accuracy and aligned recommendations with expert decisions, though LLMs tended toward conservative treatment approaches.</p>","PeriodicalId":72965,"journal":{"name":"European heart journal. Digital health","volume":"6 4","pages":"665-674"},"PeriodicalIF":4.4000,"publicationDate":"2025-06-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12282391/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"European heart journal. Digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/ehjdh/ztaf068","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/7/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"CARDIAC & CARDIOVASCULAR SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
Aims: Large language models (LLMs) have shown potential in clinical decision support, but the influence of prompt design on their performance, particularly in complex cardiology decision-making, is not well understood.
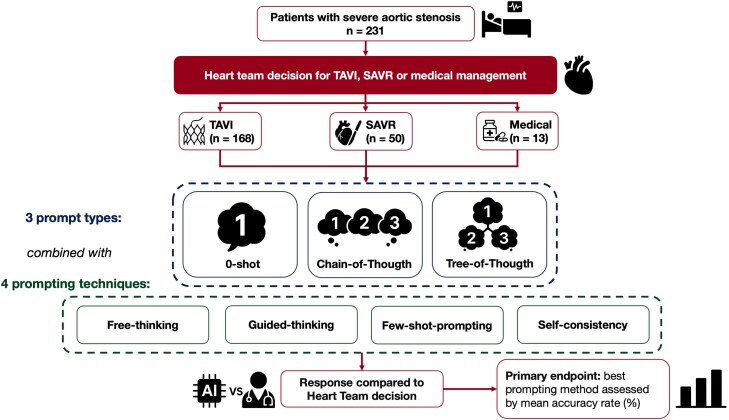
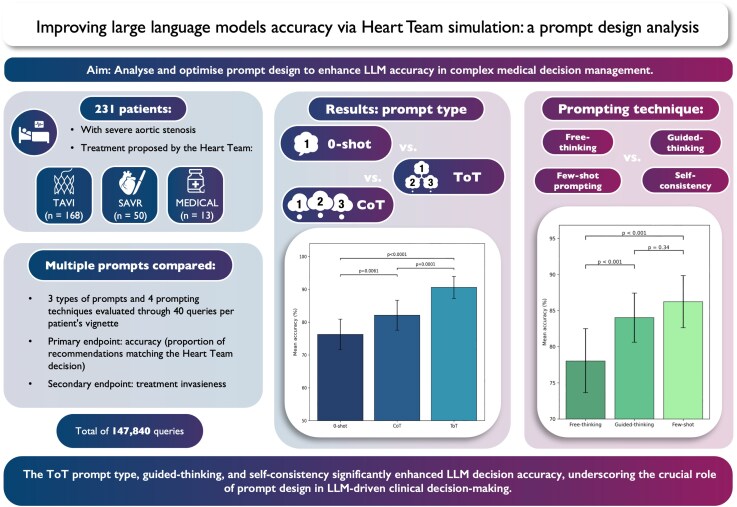
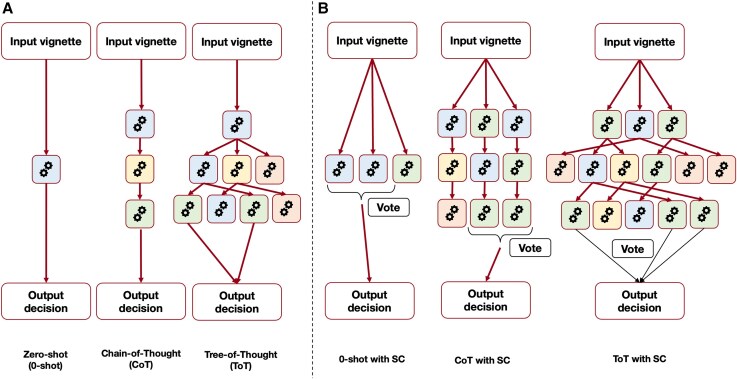
Methods and results: We retrospectively reviewed 231 patients evaluated by our Heart Team for severe aortic stenosis, with treatment options including surgical aortic valve replacement, transcatheter aortic valve implantation, or medical therapy. We tested multiple prompt-design strategies using zero-shot (0-shot), Chain-of-Thought (CoT), and Tree-of-Thought (ToT) prompting, combined with few-shot prompting, free/guided-thinking, and self-consistency. Patient data were condensed into standardized vignettes and queried using GPT4-o (version 2024-05-13, OpenAI) 40 times per patient under each prompt (147 840 total queries). Primary endpoint was mean accuracy; secondary endpoints included sensitivity, specificity, area under the curve (AUC), and treatment invasiveness. Guided-thinking-ToT achieved the highest accuracy (94.04%, 95% CI 90.87-97.21), significantly outperforming few-shot-ToT (87.16%, 95% CI 82.68-91.63) and few-shot-CoT (85.32%, 95% CI 80.59-90.06; P < 0.0001). Zero-shot prompting showed the lowest accuracy (73.39%, 95% CI 67.48-79.31). Guided-thinking-ToT yielded the highest AUC values (up to 0.97) and was the only prompt whose invasiveness did not differ significantly from Heart Team decisions (P = 0.078). An inverted quadratic relationship emerged between few-shot examples and accuracy, with nine examples optimal (P < 0.0001). Self-consistency improved overall accuracy, particularly for ToT-derived prompts (P < 0.001).
Conclusion: Prompt design significantly impacts LLM performance in clinical decision-making for severe aortic stenosis. Tree-of-Thought prompting markedly improved accuracy and aligned recommendations with expert decisions, though LLMs tended toward conservative treatment approaches.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


