Said A Salloum, Khaled Mohammad Alomari, Ayham Salloum
{"title":"DNA sequence classification for diabetes mellitus using NuSVC and XGBoost: A comparative.","authors":"Said A Salloum, Khaled Mohammad Alomari, Ayham Salloum","doi":"10.1371/journal.pone.0328253","DOIUrl":null,"url":null,"abstract":"<p><p>Diabetes Mellitus is a global health concern, characterized by high blood sugar levels over a prolonged period, leading to severe complications if left unmanaged. The early identification of individuals at risk is critical for effective intervention and treatment. Traditional diagnostic methods rely heavily on clinical symptoms and biochemical tests, which may not capture the underlying genetic predispositions. With the advent of genomics, DNA sequence analysis has emerged as a promising approach to uncover the genetic markers associated with Diabetes Mellitus. However, the challenge lies in accurately classifying DNA sequences to predict susceptibility to the disease, given the complex nature of genetic data. This study addresses this challenge by employing two advanced machine learning models, NuSVC (Nu-Support Vector Classification) and XGBoost (Extreme Gradient Boosting), to classify DNA sequences related to Diabetes Mellitus. The dataset, obtained from reputable sources like NCBI, was preprocessed using Natural Language Processing (NLP) techniques, where DNA sequences were treated as textual data and transformed into numerical features using TF-IDF (Term Frequency-Inverse Document Frequency). To handle the class imbalance in the dataset, SMOTE (Synthetic Minority Over-sampling Technique) was applied. The models were trained and validated using 10-fold cross-validation. XGBoost was trained with up to 300 boosting rounds, and performance was evaluated using accuracy, precision, recall, F1-score, ROC-AUC, and log loss. The results demonstrate that XGBoost outperformed NuSVC across all metrics, achieving an accuracy of 98%, a log loss of 0.0650, and an AUC of 1.00, compared to NuSVC's accuracy of 87%, log loss of 0.2649, and AUC of 0.95. The superior performance of XGBoost indicates its robustness in handling complex genetic data and its potential utility in clinical applications for early diagnosis of Diabetes Mellitus. The findings of this study underscore the importance of advanced machine learning techniques in genomics and suggest that integrating such models into healthcare systems could significantly enhance predictive diagnostics.</p>","PeriodicalId":20189,"journal":{"name":"PLoS ONE","volume":"20 7","pages":"e0328253"},"PeriodicalIF":2.6000,"publicationDate":"2025-07-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12273983/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"PLoS ONE","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1371/journal.pone.0328253","RegionNum":3,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
引用次数: 0
Abstract
Diabetes Mellitus is a global health concern, characterized by high blood sugar levels over a prolonged period, leading to severe complications if left unmanaged. The early identification of individuals at risk is critical for effective intervention and treatment. Traditional diagnostic methods rely heavily on clinical symptoms and biochemical tests, which may not capture the underlying genetic predispositions. With the advent of genomics, DNA sequence analysis has emerged as a promising approach to uncover the genetic markers associated with Diabetes Mellitus. However, the challenge lies in accurately classifying DNA sequences to predict susceptibility to the disease, given the complex nature of genetic data. This study addresses this challenge by employing two advanced machine learning models, NuSVC (Nu-Support Vector Classification) and XGBoost (Extreme Gradient Boosting), to classify DNA sequences related to Diabetes Mellitus. The dataset, obtained from reputable sources like NCBI, was preprocessed using Natural Language Processing (NLP) techniques, where DNA sequences were treated as textual data and transformed into numerical features using TF-IDF (Term Frequency-Inverse Document Frequency). To handle the class imbalance in the dataset, SMOTE (Synthetic Minority Over-sampling Technique) was applied. The models were trained and validated using 10-fold cross-validation. XGBoost was trained with up to 300 boosting rounds, and performance was evaluated using accuracy, precision, recall, F1-score, ROC-AUC, and log loss. The results demonstrate that XGBoost outperformed NuSVC across all metrics, achieving an accuracy of 98%, a log loss of 0.0650, and an AUC of 1.00, compared to NuSVC's accuracy of 87%, log loss of 0.2649, and AUC of 0.95. The superior performance of XGBoost indicates its robustness in handling complex genetic data and its potential utility in clinical applications for early diagnosis of Diabetes Mellitus. The findings of this study underscore the importance of advanced machine learning techniques in genomics and suggest that integrating such models into healthcare systems could significantly enhance predictive diagnostics.
期刊介绍:
PLOS ONE is an international, peer-reviewed, open-access, online publication. PLOS ONE welcomes reports on primary research from any scientific discipline. It provides:
* Open-access—freely accessible online, authors retain copyright
* Fast publication times
* Peer review by expert, practicing researchers
* Post-publication tools to indicate quality and impact
* Community-based dialogue on articles
* Worldwide media coverage
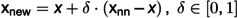
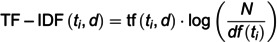

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


