Ling-Han Niu, Li Wei, Bixuan Qin, Tao Chen, Li Dong, Yueqing He, Xue Jiang, Mingyang Wang, Lan Ma, Jialu Geng, Lechen Wang, Dongmei Li
{"title":"Evaluating Large Language Models in Ptosis-Related inquiries: A Cross-Lingual Study.","authors":"Ling-Han Niu, Li Wei, Bixuan Qin, Tao Chen, Li Dong, Yueqing He, Xue Jiang, Mingyang Wang, Lan Ma, Jialu Geng, Lechen Wang, Dongmei Li","doi":"10.1167/tvst.14.7.9","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>The purpose of this study was to evaluate the performance of large language models (LLMs)-GPT-4, GPT-4o, Qwen2, and Qwen2.5-in addressing patient- and clinician-focused questions on ptosis-related inquiries, emphasizing cross-lingual applicability and patient-centric assessment.</p><p><strong>Methods: </strong>We collected 11 patient-centric and 50 doctor-centric questions covering ptosis symptoms, treatment, and postoperative care. Responses generated by GPT-4, GPT-4o, Qwen2, and Qwen2.5 were evaluated using predefined criteria: accuracy, sufficiency, clarity, and depth (doctor questions); and helpfulness, clarity, and empathy (patient questions). Clinical assessments involved 30 patients with ptosis and 8 oculoplastic surgeons rating responses on a 5-point Likert scale.</p><p><strong>Results: </strong>For doctor questions, GPT-4o outperformed Qwen2.5 in overall performance (53.1% vs. 18.8%, P = 0.035) and completeness (P = 0.049). For patient questions, GPT-4o scored higher in helpfulness (mean rank = 175.28 vs. 155.72, P = 0.035), with no significant differences in clarity or empathy. Qwen2.5 exhibited superior Chinese-language clarity compared to English (P = 0.023).</p><p><strong>Conclusions: </strong>LLMs, particularly GPT-4o, demonstrate robust performance in ptosis-related inquiries, excelling in English and offering clinically valuable insights. Qwen2.5 showed advantages in Chinese clarity. Although promising for patient education and clinician support, these models require rigorous validation, domain-specific training, and cultural adaptation before clinical deployment. Future efforts should focus on refining multilingual capabilities and integrating real-time expert oversight to ensure safety and relevance in diverse healthcare contexts.</p><p><strong>Translational relevance: </strong>This study bridges artificial intelligence (AI) advancements with clinical practice by demonstrating how optimized LLMs can enhance patient education and cross-linguistic clinician support tools in ptosis-related inquiries.</p>","PeriodicalId":23322,"journal":{"name":"Translational Vision Science & Technology","volume":"14 7","pages":"9"},"PeriodicalIF":2.6000,"publicationDate":"2025-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12279073/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Translational Vision Science & Technology","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1167/tvst.14.7.9","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"OPHTHALMOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Purpose: The purpose of this study was to evaluate the performance of large language models (LLMs)-GPT-4, GPT-4o, Qwen2, and Qwen2.5-in addressing patient- and clinician-focused questions on ptosis-related inquiries, emphasizing cross-lingual applicability and patient-centric assessment.
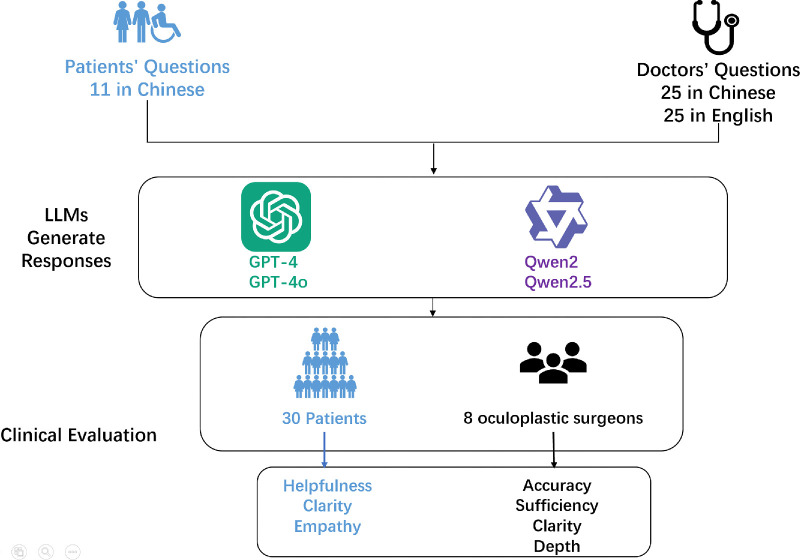
Methods: We collected 11 patient-centric and 50 doctor-centric questions covering ptosis symptoms, treatment, and postoperative care. Responses generated by GPT-4, GPT-4o, Qwen2, and Qwen2.5 were evaluated using predefined criteria: accuracy, sufficiency, clarity, and depth (doctor questions); and helpfulness, clarity, and empathy (patient questions). Clinical assessments involved 30 patients with ptosis and 8 oculoplastic surgeons rating responses on a 5-point Likert scale.
Results: For doctor questions, GPT-4o outperformed Qwen2.5 in overall performance (53.1% vs. 18.8%, P = 0.035) and completeness (P = 0.049). For patient questions, GPT-4o scored higher in helpfulness (mean rank = 175.28 vs. 155.72, P = 0.035), with no significant differences in clarity or empathy. Qwen2.5 exhibited superior Chinese-language clarity compared to English (P = 0.023).
Conclusions: LLMs, particularly GPT-4o, demonstrate robust performance in ptosis-related inquiries, excelling in English and offering clinically valuable insights. Qwen2.5 showed advantages in Chinese clarity. Although promising for patient education and clinician support, these models require rigorous validation, domain-specific training, and cultural adaptation before clinical deployment. Future efforts should focus on refining multilingual capabilities and integrating real-time expert oversight to ensure safety and relevance in diverse healthcare contexts.
Translational relevance: This study bridges artificial intelligence (AI) advancements with clinical practice by demonstrating how optimized LLMs can enhance patient education and cross-linguistic clinician support tools in ptosis-related inquiries.
期刊介绍:
Translational Vision Science & Technology (TVST), an official journal of the Association for Research in Vision and Ophthalmology (ARVO), an international organization whose purpose is to advance research worldwide into understanding the visual system and preventing, treating and curing its disorders, is an online, open access, peer-reviewed journal emphasizing multidisciplinary research that bridges the gap between basic research and clinical care. A highly qualified and diverse group of Associate Editors and Editorial Board Members is led by Editor-in-Chief Marco Zarbin, MD, PhD, FARVO.
The journal covers a broad spectrum of work, including but not limited to:
Applications of stem cell technology for regenerative medicine,
Development of new animal models of human diseases,
Tissue bioengineering,
Chemical engineering to improve virus-based gene delivery,
Nanotechnology for drug delivery,
Design and synthesis of artificial extracellular matrices,
Development of a true microsurgical operating environment,
Refining data analysis algorithms to improve in vivo imaging technology,
Results of Phase 1 clinical trials,
Reverse translational ("bedside to bench") research.
TVST seeks manuscripts from scientists and clinicians with diverse backgrounds ranging from basic chemistry to ophthalmic surgery that will advance or change the way we understand and/or treat vision-threatening diseases. TVST encourages the use of color, multimedia, hyperlinks, program code and other digital enhancements.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


