{"title":"Accuracy of large language models in generating differential diagnosis from clinical presentation and imaging findings in pediatric cases.","authors":"Jinho Jung, Michael Phillipi, Bryant Tran, Kasha Chen, Nathan Chan, Erwin Ho, Shawn Sun, Roozbeh Houshyar","doi":"10.1007/s00247-025-06317-z","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Large language models (LLM) have shown promise in assisting medical decision-making. However, there is limited literature exploring the diagnostic accuracy of LLMs in generating differential diagnoses from text-based image descriptions and clinical presentations in pediatric radiology.</p><p><strong>Objective: </strong>To examine the performance of multiple proprietary LLMs in producing accurate differential diagnoses for text-based pediatric radiological cases without imaging.</p><p><strong>Materials and methods: </strong>One hundred sixty-four cases were retrospectively selected from a pediatric radiology textbook and converted into two formats: (1) image description only, and (2) image description with clinical presentation. The ChatGPT-4 V, Claude 3.5 Sonnet, and Gemini 1.5 Pro algorithms were given these inputs and tasked with providing a top 1 diagnosis and a top 3 differential diagnoses. Accuracy of responses was assessed by comparison with the original literature. Top 1 accuracy was defined as whether the top 1 diagnosis matched the textbook, and top 3 differential accuracy was defined as the number of diagnoses in the model-generated top 3 differential that matched any of the top 3 diagnoses in the textbook. McNemar's test, Cochran's Q test, Friedman test, and Wilcoxon signed-rank test were used to compare algorithms and assess the impact of added clinical information, respectively.</p><p><strong>Results: </strong>There was no significant difference in top 1 accuracy between ChatGPT-4 V, Claude 3.5 Sonnet, and Gemini 1.5 Pro when only image descriptions were provided (56.1% [95% CI 48.4-63.5], 64.6% [95% CI 57.1-71.5], 61.6% [95% CI 54.0-68.7]; P = 0.11). Adding clinical presentation to image description significantly improved top 1 accuracy for ChatGPT-4 V (64.0% [95% CI 56.4-71.0], P = 0.02) and Claude 3.5 Sonnet (80.5% [95% CI 73.8-85.8], P < 0.001). For image description and clinical presentation cases, Claude 3.5 Sonnet significantly outperformed both ChatGPT-4 V and Gemini 1.5 Pro (P < 0.001). For top 3 differential accuracy, no significant differences were observed between ChatGPT-4 V, Claude 3.5 Sonnet, and Gemini 1.5 Pro, regardless of whether the cases included only image descriptions (1.29 [95% CI 1.16-1.41], 1.35 [95% CI 1.23-1.48], 1.37 [95% CI 1.25-1.49]; P = 0.60) or both image descriptions and clinical presentations (1.33 [95% CI 1.20-1.45], 1.52 [95% CI 1.41-1.64], 1.48 [95% 1.36-1.59]; P = 0.72). Only Claude 3.5 Sonnet performed significantly better when clinical presentation was added (P < 0.001).</p><p><strong>Conclusion: </strong>Commercial LLMs performed similarly on pediatric radiology cases in providing top 1 accuracy and top 3 differential accuracy when only a text-based image description was used. Adding clinical presentation significantly improved top 1 accuracy for ChatGPT-4 V and Claude 3.5 Sonnet, with Claude showing the largest improvement. Claude 3.5 Sonnet outperformed both ChatGPT-4 V and Gemini 1.5 Pro in top 1 accuracy when both image and clinical data were provided. No significant differences were found in top 3 differential accuracy across models in any condition.</p>","PeriodicalId":19755,"journal":{"name":"Pediatric Radiology","volume":" ","pages":"1927-1933"},"PeriodicalIF":2.3000,"publicationDate":"2025-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12394349/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Pediatric Radiology","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1007/s00247-025-06317-z","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/7/12 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"PEDIATRICS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Large language models (LLM) have shown promise in assisting medical decision-making. However, there is limited literature exploring the diagnostic accuracy of LLMs in generating differential diagnoses from text-based image descriptions and clinical presentations in pediatric radiology.
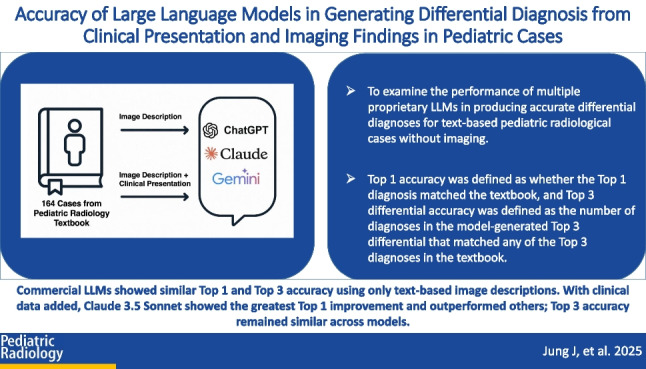
Objective: To examine the performance of multiple proprietary LLMs in producing accurate differential diagnoses for text-based pediatric radiological cases without imaging.
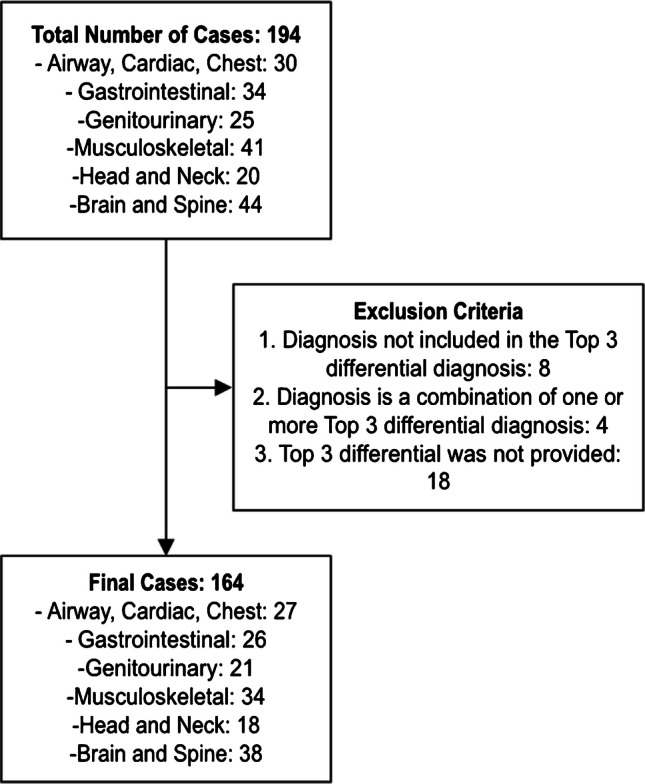
Materials and methods: One hundred sixty-four cases were retrospectively selected from a pediatric radiology textbook and converted into two formats: (1) image description only, and (2) image description with clinical presentation. The ChatGPT-4 V, Claude 3.5 Sonnet, and Gemini 1.5 Pro algorithms were given these inputs and tasked with providing a top 1 diagnosis and a top 3 differential diagnoses. Accuracy of responses was assessed by comparison with the original literature. Top 1 accuracy was defined as whether the top 1 diagnosis matched the textbook, and top 3 differential accuracy was defined as the number of diagnoses in the model-generated top 3 differential that matched any of the top 3 diagnoses in the textbook. McNemar's test, Cochran's Q test, Friedman test, and Wilcoxon signed-rank test were used to compare algorithms and assess the impact of added clinical information, respectively.
Results: There was no significant difference in top 1 accuracy between ChatGPT-4 V, Claude 3.5 Sonnet, and Gemini 1.5 Pro when only image descriptions were provided (56.1% [95% CI 48.4-63.5], 64.6% [95% CI 57.1-71.5], 61.6% [95% CI 54.0-68.7]; P = 0.11). Adding clinical presentation to image description significantly improved top 1 accuracy for ChatGPT-4 V (64.0% [95% CI 56.4-71.0], P = 0.02) and Claude 3.5 Sonnet (80.5% [95% CI 73.8-85.8], P < 0.001). For image description and clinical presentation cases, Claude 3.5 Sonnet significantly outperformed both ChatGPT-4 V and Gemini 1.5 Pro (P < 0.001). For top 3 differential accuracy, no significant differences were observed between ChatGPT-4 V, Claude 3.5 Sonnet, and Gemini 1.5 Pro, regardless of whether the cases included only image descriptions (1.29 [95% CI 1.16-1.41], 1.35 [95% CI 1.23-1.48], 1.37 [95% CI 1.25-1.49]; P = 0.60) or both image descriptions and clinical presentations (1.33 [95% CI 1.20-1.45], 1.52 [95% CI 1.41-1.64], 1.48 [95% 1.36-1.59]; P = 0.72). Only Claude 3.5 Sonnet performed significantly better when clinical presentation was added (P < 0.001).
Conclusion: Commercial LLMs performed similarly on pediatric radiology cases in providing top 1 accuracy and top 3 differential accuracy when only a text-based image description was used. Adding clinical presentation significantly improved top 1 accuracy for ChatGPT-4 V and Claude 3.5 Sonnet, with Claude showing the largest improvement. Claude 3.5 Sonnet outperformed both ChatGPT-4 V and Gemini 1.5 Pro in top 1 accuracy when both image and clinical data were provided. No significant differences were found in top 3 differential accuracy across models in any condition.
期刊介绍:
Official Journal of the European Society of Pediatric Radiology, the Society for Pediatric Radiology and the Asian and Oceanic Society for Pediatric Radiology
Pediatric Radiology informs its readers of new findings and progress in all areas of pediatric imaging and in related fields. This is achieved by a blend of original papers, complemented by reviews that set out the present state of knowledge in a particular area of the specialty or summarize specific topics in which discussion has led to clear conclusions. Advances in technology, methodology, apparatus and auxiliary equipment are presented, and modifications of standard techniques are described.
Manuscripts submitted for publication must contain a statement to the effect that all human studies have been reviewed by the appropriate ethics committee and have therefore been performed in accordance with the ethical standards laid down in an appropriate version of the 1964 Declaration of Helsinki. It should also be stated clearly in the text that all persons gave their informed consent prior to their inclusion in the study. Details that might disclose the identity of the subjects under study should be omitted.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


