Concurrent emergence of view invariance, sensitivity to critical features, and identity face classification through visual experience: Insights from deep learning algorithms.
{"title":"Concurrent emergence of view invariance, sensitivity to critical features, and identity face classification through visual experience: Insights from deep learning algorithms.","authors":"Mandy Rosemblaum, Nitzan Guy, Idan Grosbard, Libi Kliger, Naphtali Abudarham, Galit Yovel","doi":"10.1167/jov.25.8.2","DOIUrl":null,"url":null,"abstract":"<p><p>Visual experience is known to play a critical role in face recognition. This experience is thought to enable the formation of a view-invariant representation by learning which features are critical to identify faces across views. Discovering these critical features and the type of experience that is needed to uncover them is challenging. A recent study revealed a subset of facial features that are critical for human face recognition. Furthermore, face-trained deep convolutional neural networks (DCNNs) were sensitive to these facial features. These findings enable us now to ask what type of face experience is required for the network to become sensitive to these human-like critical features, and whether it is associated with the formation of a view-invariant representation and face classification performance. To that end, we systematically manipulated the number of within-identity and between-identity face images during training and examined its effect on the network performance on face classification, view-invariant representation, and sensitivity to human-like critical facial features. Results show that increasing the number of images per identity, as well as the number of identities were both required for the simultaneous development of a view-invariant representation, sensitivity to human-like critical features, and successful identity classification. The concurrent emergence of sensitivity to critical features, view invariance and classification performance through experience implies that they depend on similar features. Overall, we show how systematic manipulation of the training diet of DCNNs can shed light on the role of experience in the generation of human-like representations.</p>","PeriodicalId":49955,"journal":{"name":"Journal of Vision","volume":"25 8","pages":"2"},"PeriodicalIF":2.3000,"publicationDate":"2025-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12227020/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Vision","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1167/jov.25.8.2","RegionNum":4,"RegionCategory":"心理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"OPHTHALMOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
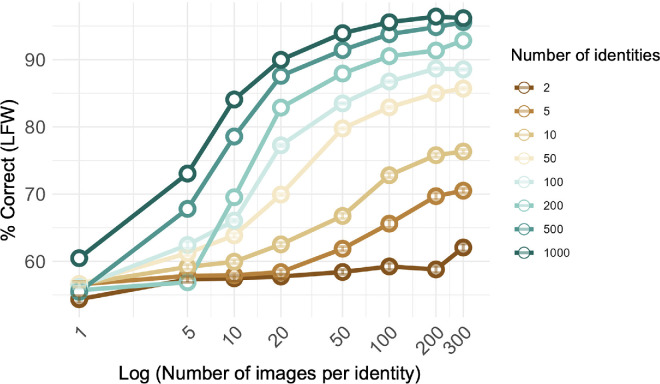
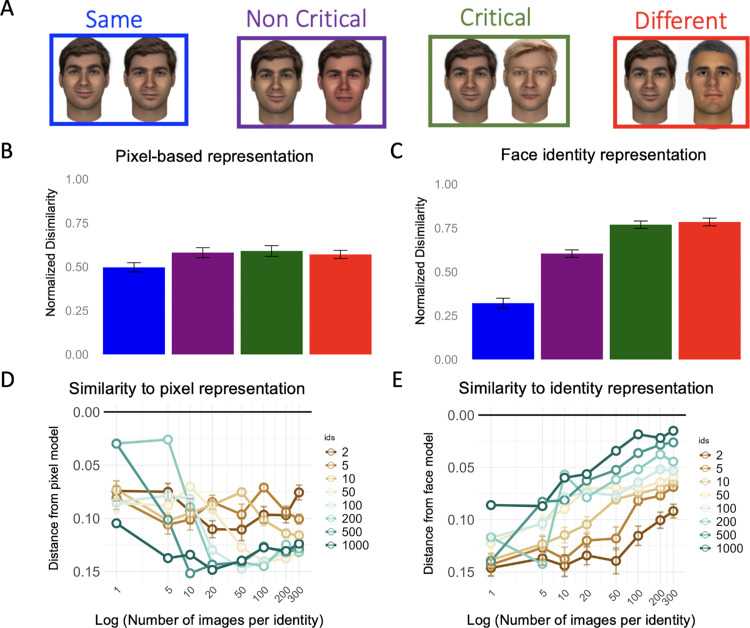
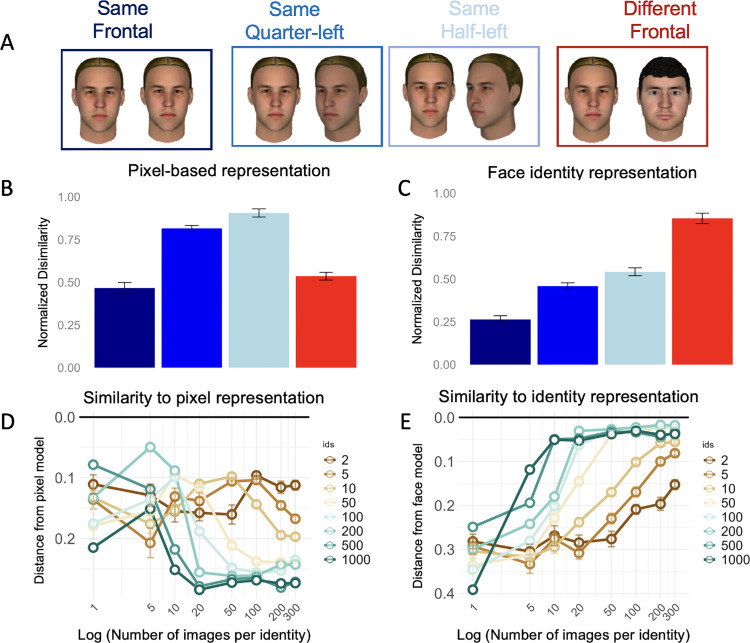
Visual experience is known to play a critical role in face recognition. This experience is thought to enable the formation of a view-invariant representation by learning which features are critical to identify faces across views. Discovering these critical features and the type of experience that is needed to uncover them is challenging. A recent study revealed a subset of facial features that are critical for human face recognition. Furthermore, face-trained deep convolutional neural networks (DCNNs) were sensitive to these facial features. These findings enable us now to ask what type of face experience is required for the network to become sensitive to these human-like critical features, and whether it is associated with the formation of a view-invariant representation and face classification performance. To that end, we systematically manipulated the number of within-identity and between-identity face images during training and examined its effect on the network performance on face classification, view-invariant representation, and sensitivity to human-like critical facial features. Results show that increasing the number of images per identity, as well as the number of identities were both required for the simultaneous development of a view-invariant representation, sensitivity to human-like critical features, and successful identity classification. The concurrent emergence of sensitivity to critical features, view invariance and classification performance through experience implies that they depend on similar features. Overall, we show how systematic manipulation of the training diet of DCNNs can shed light on the role of experience in the generation of human-like representations.
期刊介绍:
Exploring all aspects of biological visual function, including spatial vision, perception,
low vision, color vision and more, spanning the fields of neuroscience, psychology and psychophysics.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


