{"title":"A Dataset of Medical Questions Paired with Automatically Generated Answers and Evidence-supported References.","authors":"Deepak Gupta, Davis Bartels, Dina Demner-Fushman","doi":"10.1038/s41597-025-05233-z","DOIUrl":null,"url":null,"abstract":"<p><p>New Large Language Models (LLM)-based approaches to medical Question Answering show unprecedented improvements in the fluency, grammaticality, and other qualities of the generated answers. However, the systems occasionally produce coherent, topically relevant, and plausible answers that are not based on facts and may be misleading and even harmful. New types of datasets are needed to evaluate the truthfulness of generated answers and develop reliable approaches for detecting answers that are not supported by evidence. The MedAESQA (Medical Attributable and Evidence Supported Question Answering) dataset presented in this work is designed for developing, fine-tuning, and evaluating language generation models for their ability to attribute or support the stated facts by linking the statements to the relevant passages of reliable sources. The dataset comprises 40 naturally occurring aggregated deidentified questions. Each question has 30 human and LLM-generated answers in which each statement is linked to a scientific abstract that supports it. The dataset provides manual judgments on the accuracy of the statements and the relevancy of the scientific papers.</p>","PeriodicalId":21597,"journal":{"name":"Scientific Data","volume":"12 1","pages":"1035"},"PeriodicalIF":6.9000,"publicationDate":"2025-06-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12179289/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Scientific Data","FirstCategoryId":"103","ListUrlMain":"https://doi.org/10.1038/s41597-025-05233-z","RegionNum":2,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
引用次数: 0
Abstract
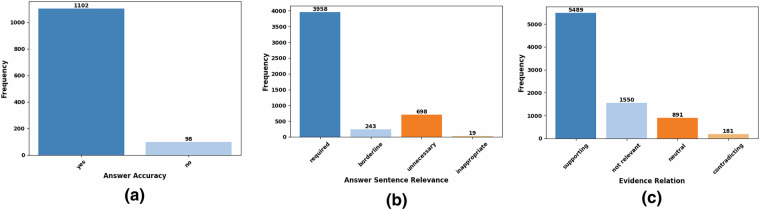
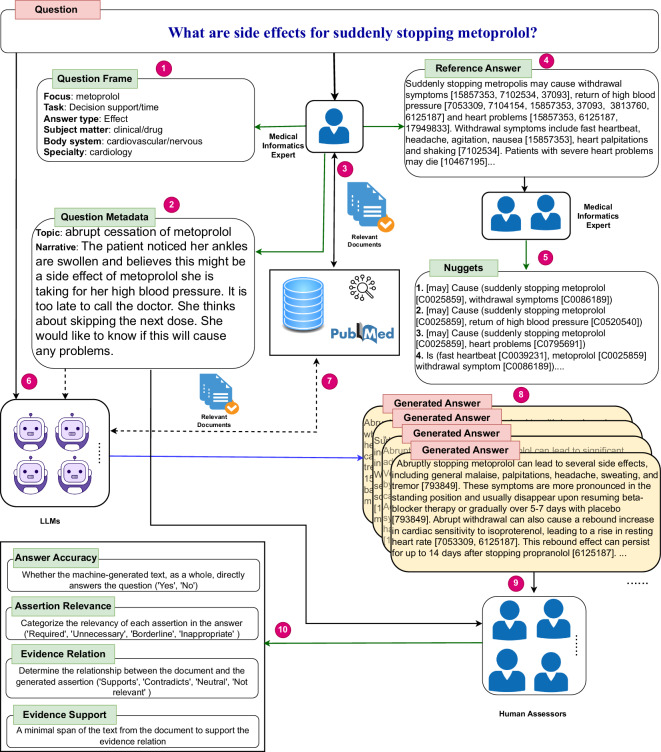
New Large Language Models (LLM)-based approaches to medical Question Answering show unprecedented improvements in the fluency, grammaticality, and other qualities of the generated answers. However, the systems occasionally produce coherent, topically relevant, and plausible answers that are not based on facts and may be misleading and even harmful. New types of datasets are needed to evaluate the truthfulness of generated answers and develop reliable approaches for detecting answers that are not supported by evidence. The MedAESQA (Medical Attributable and Evidence Supported Question Answering) dataset presented in this work is designed for developing, fine-tuning, and evaluating language generation models for their ability to attribute or support the stated facts by linking the statements to the relevant passages of reliable sources. The dataset comprises 40 naturally occurring aggregated deidentified questions. Each question has 30 human and LLM-generated answers in which each statement is linked to a scientific abstract that supports it. The dataset provides manual judgments on the accuracy of the statements and the relevancy of the scientific papers.
期刊介绍:
Scientific Data is an open-access journal focused on data, publishing descriptions of research datasets and articles on data sharing across natural sciences, medicine, engineering, and social sciences. Its goal is to enhance the sharing and reuse of scientific data, encourage broader data sharing, and acknowledge those who share their data.
The journal primarily publishes Data Descriptors, which offer detailed descriptions of research datasets, including data collection methods and technical analyses validating data quality. These descriptors aim to facilitate data reuse rather than testing hypotheses or presenting new interpretations, methods, or in-depth analyses.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


