LDM: Large tensorial SDF model for textured mesh generation
IF 2.2
4区 计算机科学
Q2 COMPUTER SCIENCE, SOFTWARE ENGINEERING
引用次数: 0
Abstract
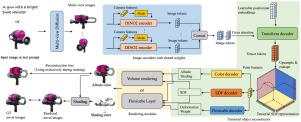
Previous efforts have managed to generate production-ready 3D assets from text or images. However, these methods primarily employ NeRF or 3D Gaussian representations, which are not adept at producing smooth, high-quality geometries required by modern rendering pipelines. In this paper, we propose LDM, a Large tensorial SDF Model, which introduces a novel feed-forward framework capable of generating high-fidelity, illumination-decoupled textured mesh from a single image or text prompts. We firstly utilize a multi-view diffusion model to generate sparse multi-view inputs from single images or text prompts, and then a transformer-based model is trained to predict a tensorial SDF field from these sparse multi-view image inputs. Finally, we employ a gradient-based mesh optimization layer to refine this model, enabling it to produce an SDF field from which high-quality textured meshes can be extracted. Extensive experiments demonstrate that our method can generate diverse, high-quality 3D mesh assets with corresponding decomposed RGB textures within seconds. The project code is available at https://github.com/rgxie/LDM.
LDM:用于纹理网格生成的大张量SDF模型
之前的努力已经成功地从文本或图像生成生产就绪的3D资产。然而,这些方法主要采用NeRF或3D高斯表示,它们不擅长生成现代渲染管道所需的光滑、高质量的几何形状。在本文中,我们提出了LDM,一种大型张量SDF模型,它引入了一种新的前馈框架,能够从单个图像或文本提示生成高保真度,光照解耦的纹理网格。我们首先利用多视图扩散模型从单个图像或文本提示生成稀疏多视图输入,然后训练基于变换的模型从这些稀疏多视图图像输入预测张量SDF场。最后,我们使用基于梯度的网格优化层来细化该模型,使其能够产生一个SDF场,从中可以提取高质量的纹理网格。大量的实验表明,我们的方法可以在几秒钟内生成具有相应分解RGB纹理的多种高质量3D网格资产。项目代码可从https://github.com/rgxie/LDM获得。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Graphical Models
工程技术-计算机:软件工程
CiteScore
3.60
自引率
5.90%
发文量
15
审稿时长
47 days
期刊介绍:
Graphical Models is recognized internationally as a highly rated, top tier journal and is focused on the creation, geometric processing, animation, and visualization of graphical models and on their applications in engineering, science, culture, and entertainment. GMOD provides its readers with thoroughly reviewed and carefully selected papers that disseminate exciting innovations, that teach rigorous theoretical foundations, that propose robust and efficient solutions, or that describe ambitious systems or applications in a variety of topics.
We invite papers in five categories: research (contributions of novel theoretical or practical approaches or solutions), survey (opinionated views of the state-of-the-art and challenges in a specific topic), system (the architecture and implementation details of an innovative architecture for a complete system that supports model/animation design, acquisition, analysis, visualization?), application (description of a novel application of know techniques and evaluation of its impact), or lecture (an elegant and inspiring perspective on previously published results that clarifies them and teaches them in a new way).
GMOD offers its authors an accelerated review, feedback from experts in the field, immediate online publication of accepted papers, no restriction on color and length (when justified by the content) in the online version, and a broad promotion of published papers. A prestigious group of editors selected from among the premier international researchers in their fields oversees the review process.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


