Enhancing vision–language contrastive representation learning using domain knowledge
IF 3.5
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
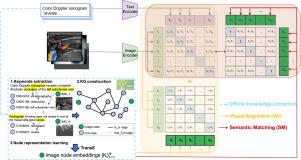
Visual representation learning plays a key role in solving medical computer vision tasks. Recent advances in the literature often rely on vision–language models aiming to learn the representation of medical images from the supervision of paired captions in a label-free manner. The training of such models is however very data/time intensive and the alignment strategies involved in the contrastive loss functions may not capture the full richness of information carried by inter-data relationships. We assume here that considering expert knowledge from the medical domain can provide solutions to these problems during model optimization. To this end, we propose a novel knowledge-augmented vision–language contrastive representation learning framework consisting of the following steps: (1) Modeling the hierarchical relationships between various medical concepts using expert knowledge and medical images in a dataset through a knowledge graph, followed by translating each node into a knowledge embedding; And (2) integrating knowledge embeddings into a vision–language contrastive learning framework, either by introducing an additional alignment loss between visual and knowledge embeddings or by relaxing binary constraints of vision–language alignment using knowledge embeddings. Our results demonstrate that the proposed solution achieves competitive performances against state-of-the-art approaches for downstream tasks while requiring significantly less training data. Our code is available at https://github.com/Wxy-24/KL-CVR.
利用领域知识增强视觉语言对比表征学习
视觉表征学习在解决医学计算机视觉任务中起着关键作用。最近的文献进展通常依赖于视觉语言模型,旨在以无标签的方式从成对字幕的监督中学习医学图像的表示。然而,这种模型的训练需要大量的数据/时间,对比损失函数所涉及的对齐策略可能无法捕捉到数据间关系所携带的全部丰富信息。我们假设在模型优化过程中,考虑医学领域的专家知识可以为这些问题提供解决方案。为此,我们提出了一种新的知识增强视觉语言对比表示学习框架,该框架包括以下步骤:(1)利用数据集中的专家知识和医学图像,通过知识图对各种医学概念之间的层次关系进行建模,然后将每个节点转换为知识嵌入;(2)通过在视觉和知识嵌入之间引入额外的对齐损失,或者通过使用知识嵌入放松视觉语言对齐的二元约束,将知识嵌入集成到视觉语言对比学习框架中。我们的结果表明,所提出的解决方案在需要更少的训练数据的同时,在下游任务中实现了与最先进方法的竞争性能。我们的代码可在https://github.com/Wxy-24/KL-CVR上获得。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Computer Vision and Image Understanding
工程技术-工程:电子与电气
CiteScore
7.80
自引率
4.40%
发文量
112
审稿时长
79 days
期刊介绍:
The central focus of this journal is the computer analysis of pictorial information. Computer Vision and Image Understanding publishes papers covering all aspects of image analysis from the low-level, iconic processes of early vision to the high-level, symbolic processes of recognition and interpretation. A wide range of topics in the image understanding area is covered, including papers offering insights that differ from predominant views.
Research Areas Include:
• Theory
• Early vision
• Data structures and representations
• Shape
• Range
• Motion
• Matching and recognition
• Architecture and languages
• Vision systems
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


