Fast self-supervised 3D mesh object retrieval for geometric similarity
IF 3.5
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
Digital 3D models play a pivotal role in engineering, entertainment, education, and various domains. However, the search and retrieval of these models have not received adequate attention compared to other digital assets like documents and images. Traditional supervised methods face challenges in scalability due to the impracticality of creating large, labeled collections of 3D objects. In response, this paper introduces a self-supervised approach to generate efficient embeddings for 3D mesh objects, facilitating ranked retrieval of similar objects. The proposed method employs a straightforward representation of mesh objects and utilizes an encoder–decoder architecture to learn the embedding. Extensive experiments demonstrate the competitiveness of our approach compared to supervised methods, showcasing its scalability across diverse object collections. Notably, the method exhibits transferability across datasets, implying its potential for broader applicability beyond the training dataset. The robustness and generalization capabilities of the proposed method are substantiated through experiments conducted on varied datasets. These findings underscore the efficacy of the approach in capturing underlying patterns and features, independent of dataset-specific nuances. This self-supervised framework offers a promising solution for enhancing the search and retrieval of 3D models, addressing key challenges in scalability and dataset transferability.
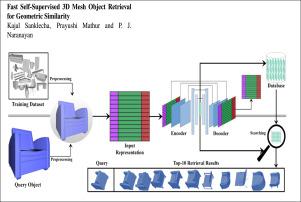
快速自监督三维网格对象检索几何相似性
数字3D模型在工程、娱乐、教育和各个领域发挥着关键作用。然而,与文档和图像等其他数字资产相比,这些模型的搜索和检索并没有得到足够的重视。传统的监督方法在可扩展性方面面临挑战,因为创建大型标记3D对象集合是不切实际的。为此,本文引入了一种自监督的方法来生成三维网格对象的高效嵌入,方便了相似对象的排序检索。该方法采用网格对象的直接表示,并利用编码器-解码器架构来学习嵌入。大量的实验证明了我们的方法与监督方法相比的竞争力,展示了它在不同对象集合中的可扩展性。值得注意的是,该方法具有跨数据集的可移植性,这意味着它在训练数据集之外具有更广泛的适用性。通过在不同数据集上进行的实验,证实了该方法的鲁棒性和泛化能力。这些发现强调了该方法在捕获潜在模式和特征方面的有效性,而不受数据集特定细微差别的影响。这种自我监督框架为增强3D模型的搜索和检索提供了一个有前途的解决方案,解决了可扩展性和数据集可移植性方面的关键挑战。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Computer Vision and Image Understanding
工程技术-工程:电子与电气
CiteScore
7.80
自引率
4.40%
发文量
112
审稿时长
79 days
期刊介绍:
The central focus of this journal is the computer analysis of pictorial information. Computer Vision and Image Understanding publishes papers covering all aspects of image analysis from the low-level, iconic processes of early vision to the high-level, symbolic processes of recognition and interpretation. A wide range of topics in the image understanding area is covered, including papers offering insights that differ from predominant views.
Research Areas Include:
• Theory
• Early vision
• Data structures and representations
• Shape
• Range
• Motion
• Matching and recognition
• Architecture and languages
• Vision systems
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


