{"title":"Effectiveness of ChatGPT for Clinical Scenario Generation: A Qualitative Study.","authors":"Faezeh Ghaffari, Mostafa Langarizadeh, Ehsan Nabovati, Mahdieh Sabery","doi":"10.22037/aaemj.v13i1.2690","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>A growing area is the use of ChatGPT in simulation-based learning, a widely recognized methodology in medical education. This study aimed to evaluate ChatGPT's ability to generate realistic simulation scenarios to assist faculty as a significant challenge in medical education.</p><p><strong>Method: </strong>This study employs a qualitative research design and thematic analysis to interpret expert opinions<b>.</b> The study was conducted in two phases. Scenario generation via ChatGPT and expert review for validation. We used ChatGPT (GPT-4) to create clinical scenarios on cardiovascular topics, including cardiogenic shock, postoperative cardiac tamponade after heart surgery, and heart failure. A panel of five experts, four nurses with expertise in emergency medicine and critical care and an anesthesia specialist, evaluated the scenarios. The experts' feedback, strengths and weaknesses, and proposed revisions from the expert discussions were analyzed via thematic analysis. Key themes and proposed revisions were identified, recorded, and compiled by the research team.</p><p><strong>Results: </strong>The clinical scenarios were produced by ChatGPT in less than 5 seconds per case. The thematic analysis identified six recurring themes in the experts' discussions: clinical accuracy, the clarity of learning objectives, the logical flow of patient cases, realism and feasibility, alignment with nursing competencies, and level of difficulty. All the experts agreed that the scenarios were realistic and followed clinical guidelines. However, they also identified several errors and areas that needed improvement. The experts identified and documented specific errors, incorrect recommendations, missing information, and inconsistencies with standard nursing practices.</p><p><strong>Conclusion: </strong>It seems that, ChatGPT can be a valuable tool for developing clinical scenarios, but expert review and refinement are necessary to ensure the accuracy and alignment of the generated scenarios with clinical and educational standards.</p>","PeriodicalId":8146,"journal":{"name":"Archives of Academic Emergency Medicine","volume":"13 1","pages":"e49"},"PeriodicalIF":2.0000,"publicationDate":"2025-05-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12145122/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Archives of Academic Emergency Medicine","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.22037/aaemj.v13i1.2690","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"EMERGENCY MEDICINE","Score":null,"Total":0}
引用次数: 0
Abstract
Introduction: A growing area is the use of ChatGPT in simulation-based learning, a widely recognized methodology in medical education. This study aimed to evaluate ChatGPT's ability to generate realistic simulation scenarios to assist faculty as a significant challenge in medical education.
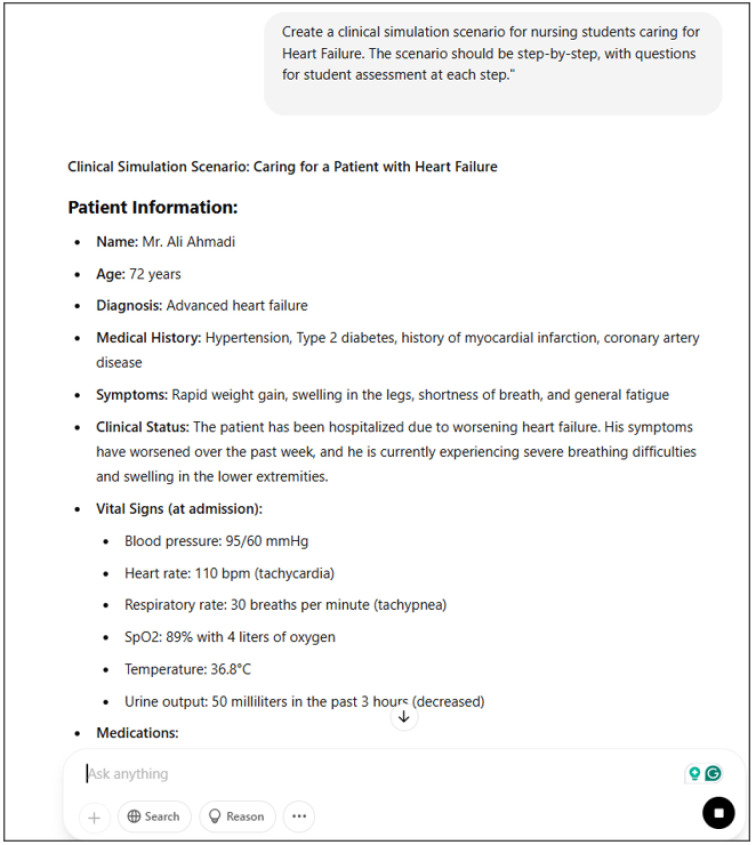
Method: This study employs a qualitative research design and thematic analysis to interpret expert opinions. The study was conducted in two phases. Scenario generation via ChatGPT and expert review for validation. We used ChatGPT (GPT-4) to create clinical scenarios on cardiovascular topics, including cardiogenic shock, postoperative cardiac tamponade after heart surgery, and heart failure. A panel of five experts, four nurses with expertise in emergency medicine and critical care and an anesthesia specialist, evaluated the scenarios. The experts' feedback, strengths and weaknesses, and proposed revisions from the expert discussions were analyzed via thematic analysis. Key themes and proposed revisions were identified, recorded, and compiled by the research team.
Results: The clinical scenarios were produced by ChatGPT in less than 5 seconds per case. The thematic analysis identified six recurring themes in the experts' discussions: clinical accuracy, the clarity of learning objectives, the logical flow of patient cases, realism and feasibility, alignment with nursing competencies, and level of difficulty. All the experts agreed that the scenarios were realistic and followed clinical guidelines. However, they also identified several errors and areas that needed improvement. The experts identified and documented specific errors, incorrect recommendations, missing information, and inconsistencies with standard nursing practices.
Conclusion: It seems that, ChatGPT can be a valuable tool for developing clinical scenarios, but expert review and refinement are necessary to ensure the accuracy and alignment of the generated scenarios with clinical and educational standards.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


