Cristian Campos, Rafael Asenjo, Javier Hormigo, Angeles Navarro
{"title":"Leveraging SYCL for Heterogeneous cDTW Computation on CPU, GPU, and FPGA","authors":"Cristian Campos, Rafael Asenjo, Javier Hormigo, Angeles Navarro","doi":"10.1002/cpe.70142","DOIUrl":null,"url":null,"abstract":"<p>One of the most time-consuming kernels of a recent epileptic seizure detection application is the computation of the constrained Dynamic Time Warping (cDTW) Distance Matrix. In this paper, we explore the design space of heterogeneous CPU, GPU, and FPGA implementations of this kernel using SYCL as a programming model. First, we optimize the CPU implementation leveraging the SIMD capability of SYCL and compare it with the latest C++26 SIMD library. Next, we tune the SYCL code to run on an on-chip GPU, iGPU, as well as on a discrete NVIDIA GPU, dGPU. We also develop a SYCL implementation on an Intel FPGA. On top of that, we exploit simultaneous co-processing on CPU+GPU and CPU+FPGA platforms by extending a previous heterogeneous scheduling framework to now support 2D partitioning strategies. Our evaluations demonstrate that SYCL seems well suited to exploit the SIMD capabilities of modern CPU cores and shows promising results for accelerating devices, both in terms of performance and energy efficiency. Moreover, we find that our scheduler enables the efficient co-execution of work among the computing devices, and the results demonstrate that dynamic and adaptive partitioning strategies perform efficiently with overheads below 4%.</p>","PeriodicalId":55214,"journal":{"name":"Concurrency and Computation-Practice & Experience","volume":"37 15-17","pages":""},"PeriodicalIF":1.5000,"publicationDate":"2025-06-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/cpe.70142","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Concurrency and Computation-Practice & Experience","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/cpe.70142","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
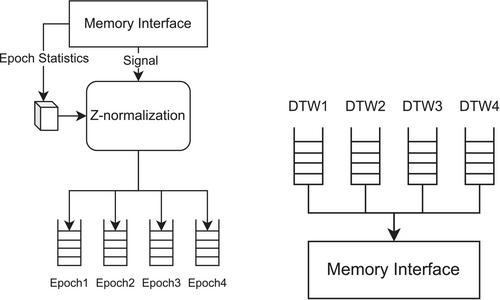
One of the most time-consuming kernels of a recent epileptic seizure detection application is the computation of the constrained Dynamic Time Warping (cDTW) Distance Matrix. In this paper, we explore the design space of heterogeneous CPU, GPU, and FPGA implementations of this kernel using SYCL as a programming model. First, we optimize the CPU implementation leveraging the SIMD capability of SYCL and compare it with the latest C++26 SIMD library. Next, we tune the SYCL code to run on an on-chip GPU, iGPU, as well as on a discrete NVIDIA GPU, dGPU. We also develop a SYCL implementation on an Intel FPGA. On top of that, we exploit simultaneous co-processing on CPU+GPU and CPU+FPGA platforms by extending a previous heterogeneous scheduling framework to now support 2D partitioning strategies. Our evaluations demonstrate that SYCL seems well suited to exploit the SIMD capabilities of modern CPU cores and shows promising results for accelerating devices, both in terms of performance and energy efficiency. Moreover, we find that our scheduler enables the efficient co-execution of work among the computing devices, and the results demonstrate that dynamic and adaptive partitioning strategies perform efficiently with overheads below 4%.
期刊介绍:
Concurrency and Computation: Practice and Experience (CCPE) publishes high-quality, original research papers, and authoritative research review papers, in the overlapping fields of:
Parallel and distributed computing;
High-performance computing;
Computational and data science;
Artificial intelligence and machine learning;
Big data applications, algorithms, and systems;
Network science;
Ontologies and semantics;
Security and privacy;
Cloud/edge/fog computing;
Green computing; and
Quantum computing.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


