{"title":"Evidence from counterfactual tasks supports emergent analogical reasoning in large language models.","authors":"Taylor W Webb, Keith J Holyoak, Hongjing Lu","doi":"10.1093/pnasnexus/pgaf135","DOIUrl":null,"url":null,"abstract":"<p><p>A major debate has recently arisen concerning whether large language models (LLMs) have developed an emergent capacity for analogical reasoning. While some recent work has highlighted the strong zero-shot performance of these systems on a range of text-based analogy tasks, often rivaling human performance, other work has challenged these conclusions, citing evidence from so-called \"counterfactual\" tasks-tasks that are modified so as to decrease similarity with materials that may have been present in the language models' training data. Here, we report evidence that language models are also capable of generalizing to these new counterfactual task variants when they are augmented with the ability to write and execute code. The results further corroborate the emergence of a capacity for analogical reasoning in LLMs and argue against claims that this capacity depends on simple mimicry of the training data.</p>","PeriodicalId":74468,"journal":{"name":"PNAS nexus","volume":"4 5","pages":"pgaf135"},"PeriodicalIF":3.8000,"publicationDate":"2025-05-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12107539/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"PNAS nexus","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/pnasnexus/pgaf135","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/5/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
引用次数: 0
Abstract
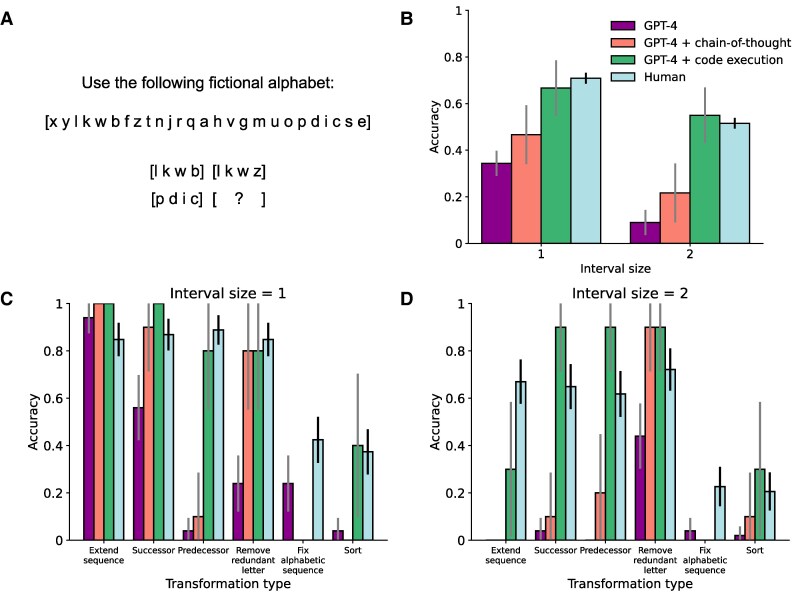
A major debate has recently arisen concerning whether large language models (LLMs) have developed an emergent capacity for analogical reasoning. While some recent work has highlighted the strong zero-shot performance of these systems on a range of text-based analogy tasks, often rivaling human performance, other work has challenged these conclusions, citing evidence from so-called "counterfactual" tasks-tasks that are modified so as to decrease similarity with materials that may have been present in the language models' training data. Here, we report evidence that language models are also capable of generalizing to these new counterfactual task variants when they are augmented with the ability to write and execute code. The results further corroborate the emergence of a capacity for analogical reasoning in LLMs and argue against claims that this capacity depends on simple mimicry of the training data.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


